Subtask Prediction

At a glance
- Task awareness. A dedicated subtask prediction module tells the policy which phase of a long-horizon task is currently active, eliminating a major source of long-horizon failures.
- Video-native perception. Our Subtask Predictor processes the last frames of visual history.
- Drop-in conditioning. Subtask embeddings feed directly into the world model as a conditioning signal before candidate futures are generated, making the planning loop task-phase-aware without changing the downstream action pipeline.
- 95% classification accuracy on our evaluation set, with measurable gains in end-to-end task success rate over policies without subtask conditioning.
Introduction
Cortex 2.0 introduced world-model-based planning into our manipulation stack: before committing to an action, the robot imagines candidate futures and selects the most promising one. This addresses the question of what to do next. But in long-horizon industrial workflows such as returns handling, kitting, or multi-step assembly, there is a complementary question the policy must answer: where am I in the overall task?
Consider a returns handling workflow. The robot must open a parcel, identify the item, pick it, classify its condition, and place it into the correct bin. A reactive policy can execute each atomic action well, but without explicit awareness of the current task phase, it is prone to a subtle class of failures: not misexecuting a grasp, but misunderstanding which grasp to execute, or attempting a scan before the item is fully extracted. These failures compound over long horizons and are difficult to recover from because the error is not in the motion but in the context.
The subtask prediction module addresses this by continuously classifying the current phase of the task from visual history. Rather than relying on hand-drafted state machines or language-based task decomposition, we train our Subtask Predictor, a VLM, to recognize subtask boundaries directly from what the robot sees. The classified subtask is embedded and fed into the world model as a conditioning input, so that the candidate future rollouts are generated with awareness of the task phase to be executed.
Pick & Place: 2 subtasks

Returns Handling: 6 subtasks

Why Subtask Awareness Matters
Most manipulation failures in production are not about the physics of grasping. They are about sequencing. A robot that is excellent at picking but confused about whether it should be picking or placing will fail the overall task. Short tasks, for example pick and place, where start and end states are clearly defined, work reliably with reactive policies. But more complex workflows are compositions of many such steps, and the transitions between them are where things break. Two of our core deployments showcase this:
Returns handling
A single returns cycle involves parcel opening, item extraction, item inspection and grading, and item repacking. Each phase has different manipulation requirements: from careful unpacking versus precise grading versus clean repacking. Without explicit phase awareness, the policy occasionally applies the wrong manipulation strategy to the current context, leading to fumbled extractions or misrouted items.
Kitting
Kitting workflows require the robot to pick specific items in order and place them into compartmentalized packaging. An item might be placed to the same position as the preceding one or the order might be finished too soon while some items are still missing. The longer and more complex the kit, the more critical it becomes that the policy tracks where it is in the sequence.
Cross-Embodiment and Multi-Tasks:
We explore subtask predictions across our research tasks and embodiments:
- Mobile Trossen: Approaching storage unit, opening storage unit, picking bottle from storage unit, placing bottle into container, closing storage unit
- Humanoid Bottle: Detecting approaching human, picking water bottle, handing bottle to person
- Dualarm Candy: Picking box, moving box to fill station, picking candy, placing candy into box, closing box, placing box into compartment
Reducing Action Distribution Bias
Subtask conditioning can also helps reduce action distribution bias. When the world model knows which phase is active, it is less likely to default to the most common manipulation primitive in the training data and more likely to generate futures that reflect the dynamics appropriate to the current task phase.
Architecture
The subtask prediction module is a lightweight task-context module that feeds into the Cortex 2.0 planning loop, conditioning the world model with task-phase context before planning begins. At a high level, the subtask prediction module has two aligned streams with one video and one text encoder.
Visual encoding with the Subtask Predictor
The Subtask Predictor ingests the most recent frames of visual history from the robot's camera stream. A single frame cannot tell apart "approaching to pick" from "approaching to place": the hand is in roughly the same position, the gripper looks the same, only the recent history differs. By processing multiple frames of past history at once, the model resolves these ambiguities directly from motion and scene dynamics rather than from hand-drafted heuristics. This is the same observation that motivates temporal aggregation in the action-segmentation literature.
To aggregate this sequence into a fixed-size representation, we append a small set of learned subtask query tokens. The Subtask Predictor encodes these frames into a joint embedding that captures both the current scene state and the temporal dynamics of recent actions.
Text stream and contrastive training
Parallel to the vision stream, a small text encoder maps each ground-truth subtask description (for example, "folding jeans" or "placing item to box") to a Subtask Query Embedding zt of the same dimensionality as zv, also L2-normalized.
Both streams are trained jointly. For every training clip, the model produces two embedding: zv and zt. These two embeddings describe the same underlying event from two different modalities and the training objective is to align these two. Concretely, we minimize a symmetric InfoNCE loss with learned temperature, identical to the contrastive objective used in CLIP. Within each batch of N (clip, description) pairs, the loss maximizes the cosine similarity of the matching pairs (positive subtask) and minimizes it for all mismatched pairs (negative subtasks) in both directions (clip-to-text and text-to-clip). This shapes the visual representation so that proximity in the projected space corresponds to semantic similarity of task phase.
This makes the design open-vocabulary: the vision encoder has lessened a general mapping from videos to a language-shaped embedding space. Because the embedding space is shaped by language rather than by a fixed class list, introducing a new subtask requires only adding its description to the bank without retraining of the classification layer. This works well when the new subtask is a recomposition of familiar primitives and visual elements; genuinely novel manipulation skills, of course, still require additional training data.
At inference the architecture collapses to a single stream. The text encoder is not loaded and the robot never sees ground-truth labels at deployment. Only the vision stream runs, producing an observation embedding zv that already lives in the language-aligned subtask space.
Integration with Cortex 2.0
The continuous observation embedding zv and the decoded discrete subtask label are fed as conditioning inputs into the world model, before candidate future trajectories are generated. The world model's rollouts are task-phase-aware from the start: when predicting future states, it knows whether the robot is currently in a parcel-opening phase or an inspection phase, and generates candidate futures accordingly. The downstream PRO scoring and action generation then operate on rollouts that already reflect the correct task context.
This is a key architectural choice. Rather than correcting the policy after planning (by conditioning the action expert), we condition the planning itself. The world model generates fundamentally different candidate futures depending on the current subtask. The PRO module then scores these phase-appropriate candidates, and the VLA executes the best one, making the entire planning loop is subtask-aware, not just the final action output.
Inference runs continuously and asynchronously. Whenever the previous classification completes, a new inference is triggered immediately on the latest frames.
Evaluation
We evaluate the subtask prediction module along two axes: classification accuracy of the predictor itself, and the downstream impact on end-to-end task success when the policy is conditioned on subtask predictions.
Subtask classification accuracy
On a held-out test set of annotated manipulation sequences, the Subtask Predictor achieves 94.6% frame-level classification accuracy. We measure this by comparing the model's per-frame subtask predictions against ground-truth annotations produced by human labelers on a held-out set of manipulation sequences not seen during training. Each frame is assigned a ground-truth subtask label, and accuracy is computed as the fraction of frames where the predicted label matches. Errors concentrate at subtask boundaries rather than systematic misclassifications of entire phases.
End-to-end task success
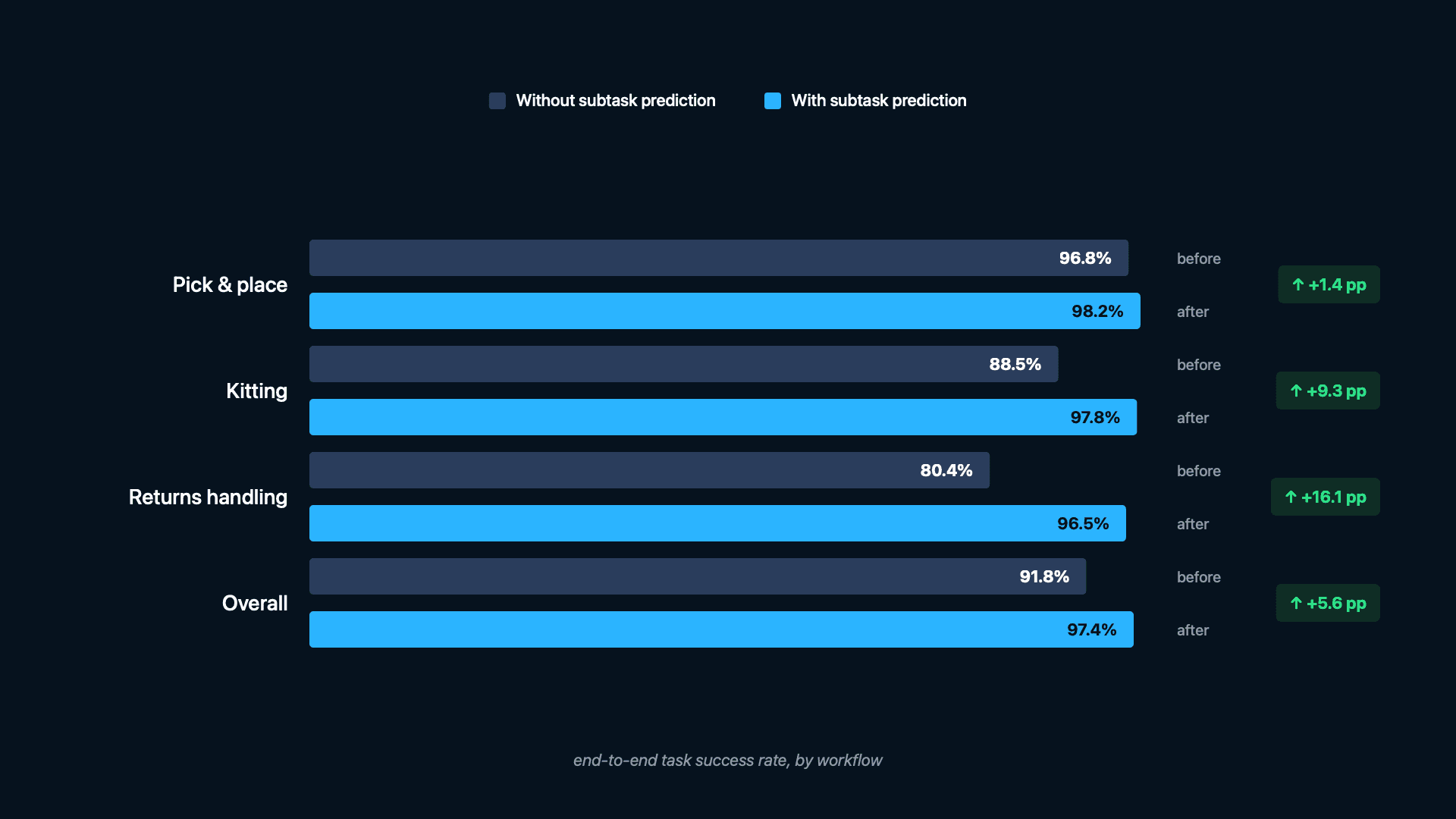
We compare the full Cortex 2.0 policy with and without subtask prediction across our deployment workflows on the end-to-end task success.
The evaluation set has an uneven distribution of individual tasks, weighted toward pick-and-place, followed by returns handling and kitting. Across our deployment workflows, subtask conditioning lifts end-to-end task success from 91.8% to 97.4%. The effect scales with task length: returns handling (5+ phase transitions) sees the largest gain at 16.1 percentage points (pp), kitting 9.3 pp, while short pick-and-place tasks show minimal improvement (1.4 pp) as expected. With few transitions, the reactive policy already has sufficient context from the current observation.
Failure analysis
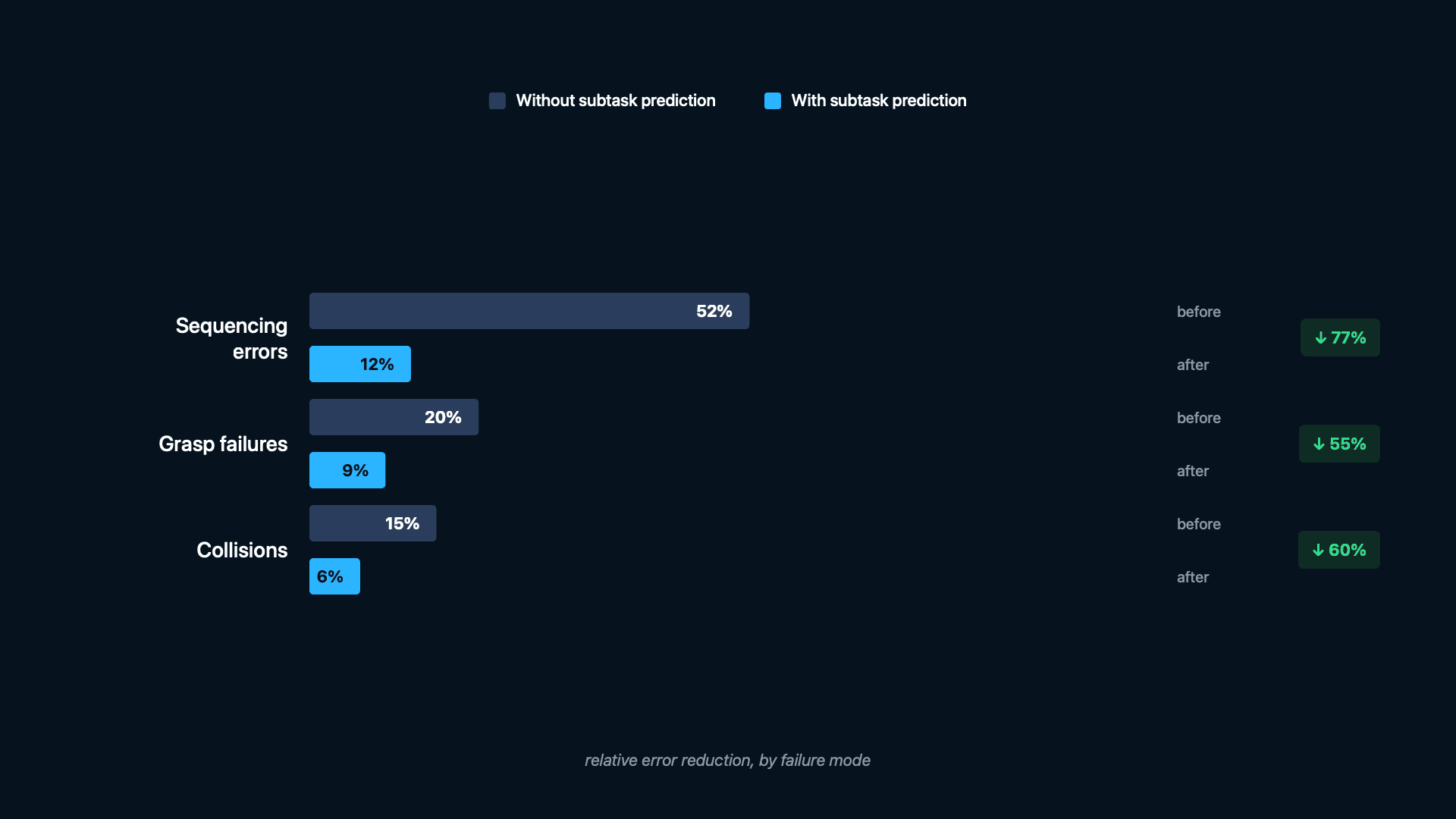
Without subtask prediction, the most common failure mode in long-horizon tasks is not a missed grasp or a collision, but the policy applying the wrong manipulation strategy for the current phase. For example, attempting a placement motion when the item has not yet been fully extracted, or reinitiating a pick sequence after the item is already grasped. These failures are particularly costly because they often require human intervention to resolve, since the robot's state has diverged from any recoverable trajectory.
With subtask prediction, this class of failures is substantially reduced. The policy receives explicit signal about the current phase, which prevents the most egregious sequencing errors. Residual failures tend to be within-phase execution errors (e.g., a grasp that slips) rather than cross-phase confusion.
Successful execution of all subtasks
Failure mode: Sequencing errors
Failure mode: Grasp failures
Failure mode: Collisions
Where We Are Today
The subtask prediction module is currently deployed alongside Cortex 2.0 in our returns handling and kitting workflows. We are expanding the set of subtask descriptions as we onboard additional tasks, and increasing the diversity of training data to improve robustness across different warehouse environments and object distributions.
The contrastive text embedding approach already moves us toward open-vocabulary subtask discovery where the model identifies task phases from data without manual annotation of a fixed class list. This reduces the engineering effort required to deploy subtask prediction on new workflows and enables the system to adapt to novel task structures at deployment time.
Combined with the planning capabilities of Cortex 2.0, subtask prediction moves us closer to manipulation systems that not only reason about what to do next, but understand where they are in the broader context of the task. This capability will help us solve more reliably long-horizon autonomy.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles