Perception in robotics – robots getting smarter

This article is just something that I would like to talk about as if we were having a conversation (but I would keep talking for a few minutes straight hahaha). So get your favorite drink and let’s talk about robots and how “smart” they have become.
You likely watched videos of robots doing fascinating things in the past months. And maybe while watching such videos, you might have thought “Wow, this is amazing. Can robots do that now? They are getting smarter every day”. Some examples are Figure 01 humanoid manipulating objects and Scythe robot cutting the grass autonomously.
Yeah, there has been a significant improvement in what robots can do nowadays. However, are they getting smarter? If so, why and how? Let’s pause here and go back in robotics history from the perspective of the robots’ perception of two problems: Simultaneous Localization and Mapping (SLAM) and bin picking.
Robots’ perception in the past and present
But first, what is “perception” in the field of robotics? In case you don’t know, it refers to the ability of a robot to sense and interpret the environment using its various sensors such as cameras, LiDAR, radar, or touch sensors. It involves collecting and processing sensor data to extract meaningful information about the environment.
Based on this simple definition, you can imagine that perception enables robots to observe their surroundings, make informed decisions, and navigate autonomously in dynamic and complex environments.
Perception is crucial for SLAM in robotics. Again, if you don’t know, SLAM is a fundamental problem in robotics. It involves a robot navigating an unknown environment while simultaneously building a map of that environment and localizing itself within it.
In 2016, Cadena and other authors published a scientific paper titled “Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age”. In their work, they reviewed over 30 years of work in SLAM and grouped these years of work as Classical (1986–2004), Algorithmic-analysis (2004–2015), and Robust-perception (2015-present) ages. Let’s go briefly through each of them now.
Classical age: It introduces the main ways SLAM handles uncertainty, like with Extended Kalman Filters, Rao-Blackwellized Particle Filters, and maximum likelihood estimation. It also talks about the basic challenges in making sure everything runs smoothly and connecting the right pieces of data. Two examples of SLAM from this age are shown below.

Environment representation generate by techniques from the Classical age. Source: Left [1] and right [2]
In general, you can see in the image that the first proposed SLAM systems could detect and represent the obstacles from the environment in the map. The most popular sensors used for mapping were ultrasonic and LiDAR.
Algorithmic-analysis age: Researchers looked into the basic features of SLAM, such as how well it tracks locations over time, if it reliably gets to the right answer, and how it handles lots of data. They found out that having sparse data helps SLAM work faster and better. This is also when they started creating the main free-to-use SLAM software, such as Gmapping and ORB-SLAM.
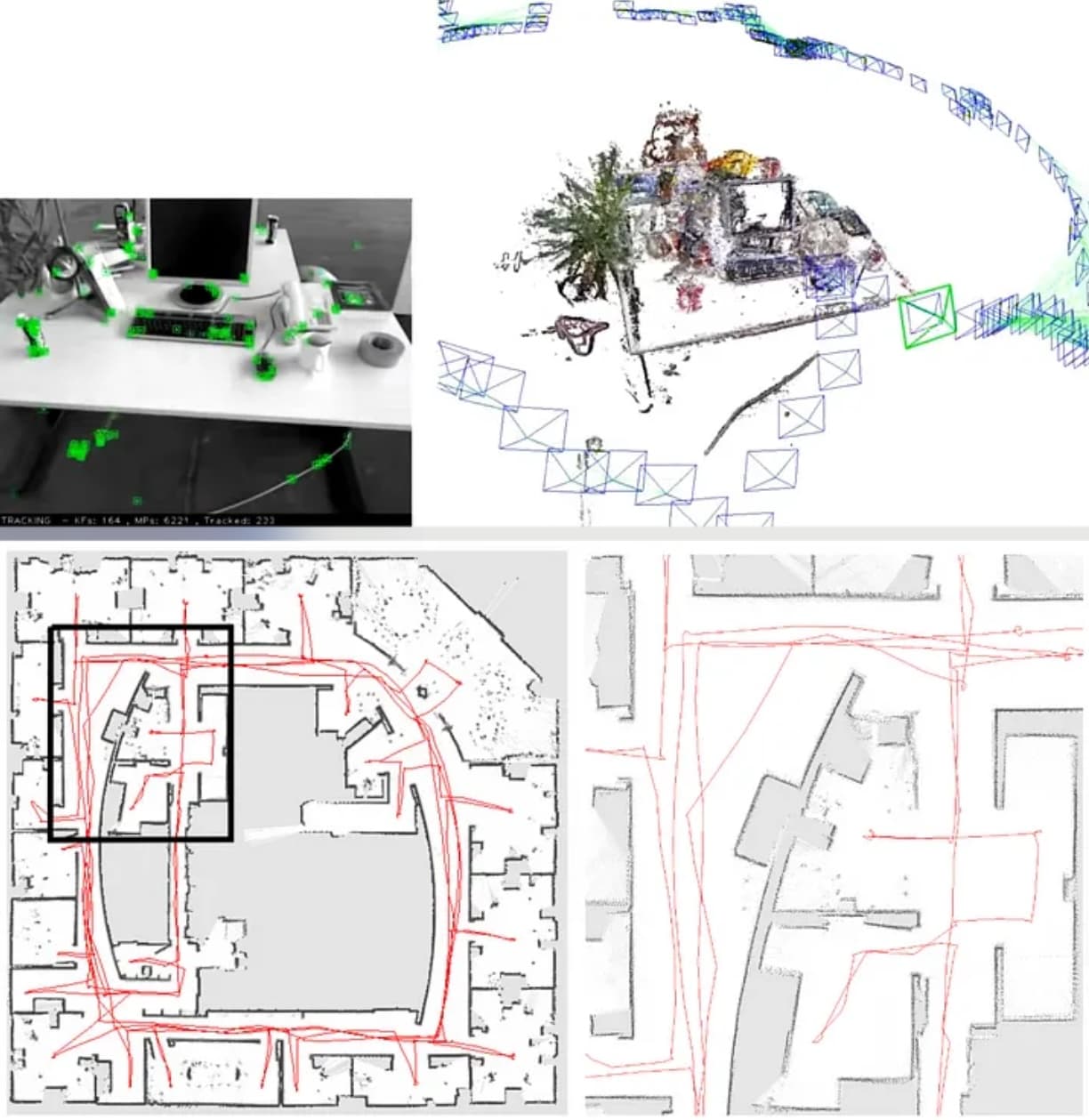
Environment representation generate by techniques from the Algorithmic-analysis age. Source: Top [3] and down [4]
Taking advantage of the foundations from the previous age, cameras and other visual sensors became more popular at this age, and the term “Visual-SLAM” was proposed. Additionally, the community introduced different SLAM techniques with 3D representations of the environment.
Robust-perception age: The SLAM system isn’t just about mapping out shapes — it goes beyond basic geometry reconstruction to obtain a high-level understanding of the environment, considering things like the meaning of objects (semantics) and even the physics involved; it focuses on relevant details, filtering out the extra noise from sensor data to help the robot accomplish its tasks. Depending on what the robot needs to do, it adapts its maps to fit the job at hand.

Environment representation generated by Zoox's system. Source: [5]

Environment representation generated by Zoox's system. Source: [5]

Environment representation generated by Zoox's system. Source: [5]
If you look closely at these images, you’ll notice many details. Objects in the scene are understood as parts of the environment, objects from the same class are labeled with the same color in their bounding boxes, and the 3D data from LiDARs and radars are combined with 2D images from cameras. Additionally, different objects are combined to extract more information from the scene, as it happens in the last image with the white car and its blinkers, reverse, and brake lights on.
Perception in bin-picking
Bin picking stands as a fundamental challenge in the fields of computer vision and robotics. The robotic arm is equipped with sensors to efficiently grasp objects with varying orientations from a bin (or container) using either a suction gripper, parallel gripper, or alternative robotic tool. Although this is a different problem and not mentioned in Cadena’s paper, the same age groups from SLAM can be applied here (and this is my opinion).
One of the most popular approaches for this problem was based on point cloud (PC) registration, from the period of the Algorithmic-analysis age. The 3D shape of the picking item should be known beforehand, and sensors were used to scan the bin before every pick. A 3D PC would be generated from this scanning, which then would be sent to a PC registration algorithm. This algorithm was responsible for finding a match between the picking item and the PC from the bin. The image below illustrates this process.

Robot picking with PC-based approach. Source: [7]
Even though this approach worked at the time, you can easily understand its limitations. For example, there could be only one item type per bin, otherwise the computation cost to match multiple picking items with the PC from the bin would be huge. Additionally, this approach doesn’t scale fast, as for new items it would be necessary to scan the item to generate its 3D shape representation (or ask the manufacturer for the CAD files). The new approach to deal with bin-picking is also introduced during the Robust-perception age.
Die Verbesserung der Wahrnehmung dieses Problems und ein besseres Verständnis der Szene (Semantik) würden die Leistung der Roboter erheblich beeinflussen. Genau das tut Sereact, indem es große linguistische und visuelle Sprachmodelle (LLMs bzw. VLMs) in das System von Sereact integriert.
It is capable of getting the source bin empty, even though there are multiple types of items inside. Additionally, Sereact's system has achieved a generalization level that makes them pick new (items that the system has never seen before) items right away.
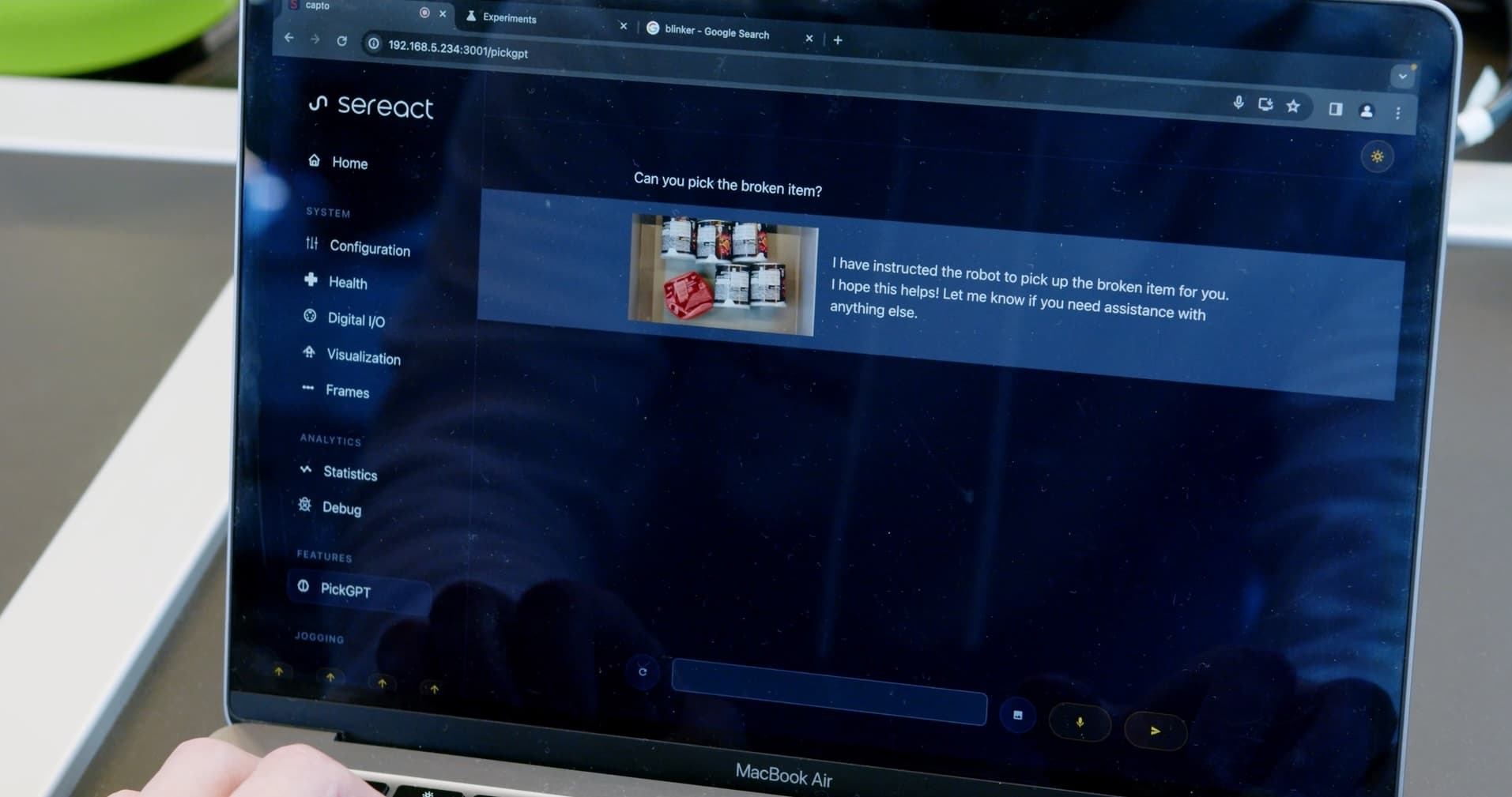
Chat interface of Sereact's PickGPT, Source: [8]
Lastly, besides the part of fast scaling and adapting to new items, this improvement in perception allows them to deal with other human-level commands, such as: “Pick all the food items”, “pick the toys”, or even “Get me the items that I can play with”. In the example above, we see Sereact's system picking the broken item from the bin.
Now that we have covered the evolution of perception in robotics, we can move to the best part of this article.
The impact and pace of the evolution in perception of robotics
I included some images from the main works from each age, and I didn’t do that just to make this article easier to read. If you look at the images from the Classical age, you’ll notice that we could barely represent the obstacles from the environment. Most of the built maps were in 2D, flatting out the 3D obstacles from environments. The different objects from the environment were all labeled as “obstacles”, and as long as the robots avoided them, it was fine.
With the advances in visual sensors, the algorithmic analysis age improved the perception by having more 3D maps and adding colors to the environment. Even though I haven’t mentioned it, this age also started filtering out dynamic parts of the scene. So, from 2004 to 2015, the biggest difference was the exploration of 3D maps and the addition of color information to these maps. I know that I’m making things simpler here, but my point is that for 11 years, things haven’t evolved that much in terms of perception in robotics.
On the other hand, the Robust-perception age makes the two other ages look like nothing. I still remember when I read Cadena’s work in 2016 while I was writing my Ph.D. project proposal. In that paper, they wrote a sentence that stuck in my mind:
“the limitations of purely geometric maps have been recognized and this has spawned a significant and ongoing body of work in the semantic mapping of environments, to enhance robot’s autonomy and robustness, facilitate more complex tasks (e.g. avoid muddy-road while driving), move from path-planning to task-planning, and enable advanced human-robot interaction.”
When you think about it, it makes so much sense. The perception in robotics until 2015 focused on building a solid foundation (in terms of approaches and techniques) and improving them. Once that part was robust enough, the research community and the industry realized that labeling the environment as “free”, “occupied” or “unknown” was not enough. That’s when they decided to go for Semantics, inferring high-level information from the environment, including but not limited to names and categories of different objects, rooms, and locations.
It blows my mind that from 2015 to 2020, Zoox and Sereact managed to achieve that level of understanding of the environment. Let’s discuss some details from them, and I’ll include the images here again so that you don’t need to scroll up.
In this part below, you can see that the autonomous car can understand when people are sitting and not walking. Besides, it can also understand the human gesture meaning it could go ahead.

Environment representation generated by Zoox's system. Source: [5]
In this other case, the car understands that there’s a person on the scene, wearing a safety vest and a construction hat. He is also holding a traffic sign. That means this person is not a regular person, but a road construction worker signing for the car to stop.
Environment representation generated by Zoox's system. Source: [5]
Lastly, in this case, the car understands that a parked car has one of its doors open, meaning that a person may come out of it. In this situation, the Zoox car drives more carefully to prevent any accidents.

Environment representation generated by Zoox's system. Source: [5]
I mentioned that I also would cover the improvements in the perception of the bin picking field. Here I bring a good example of that from Sereact. In this case, the human asks the robot to pick the broken item out of the bin. The source bin contains six Pringles cans, and one of them is smashed. The perception part of the system can understand that and it picks the smashed can that is broken.

Sereact's PickGPT executes command, Source: [8]
Summary
We are living in the Robust-perception age, where the perception in robotics considers the semantics of the environment. This allows robots to perform high-level tasks, such as picking the broken items from a bin as Sereact has shown, or anticipating accidents as Zoox does. For us humans is quite obvious and simple to understand what “broken” means, but can you define what “broken” means? It’s almost impossible to set rules and characteristics that describe this condition for all items in a warehouse (a broken can is different from a broken mug, for example).
Under the hood, such semantic understanding comes from LLM and VLM, that combine textual and visual information. It’s only when robots understand that the clothing of a person implies that they have different roles in the scene (as we have seen with the road construction worker) that they can properly react to this person.
Robots are doing more fascinating things every day, and this fast-paced improvement is, in my opinion, thanks to the semantic understanding of the environment from these robots. Nowadays we are seeing robots getting to human-level instead of the other way around.
Of course, there have been significant improvements in the hardware part of robotics too. I’m writing this article in the same week that Boston Dynamics retired the hydraulic Atlas and launched the fully electrical version. However, I feel that the software improvement in perception is more significant for robots performing high-level tasks.
About the main question from this article, I have an answer. Once I heard that a person is smart when they know how to use their knowledge instead of just accumulating it. So if we consider that robots are using their “novel” knowledge to solve more complex tasks, they are indeed getting smarter.
References
- Newman, Paul, et al. “Explore and return: Experimental validation of real-time concurrent mapping and localization.” ICRA, 2002.
- Thrun, Sebastian. “An Online Mapping Algorithm for Teams of Mobile Robots”. Carnegie-Mellon Univ Pittsburgh PA School of Computer Science, 2000.
- Mur-Artal, R., Montiel, J.M.M., and Tardos, J.D. “ORB-SLAM: a versatile and accurate monocular SLAM system.” IEEE Transactions on Robotics. 2015.
- Grisetti, G., Stachniss, C., and Burgard, W. “Improving grid-based slam with rao-blackwellized particle filters by adaptive proposals and selective resampling.” ICRA. 2005.
- Extracted from https://www.youtube.com/watch?v=5E2NYmgvo3E
- Cadena C, Carlone L, Carrillo H, Latif Y, Scaramuzza D, Neira J, Reid I, Leonard JJ. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Transactions on robotics. 2016.
- Extracted from https://www.youtube.com/watch?v=gRV4KvIDn9Y&ab_channel=T³TipsTricksTests
- Extracted from https://www.youtube.com/watch?v=_ieObX5f_ws&ab_channel=Sereact
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles