PickGPT – a Large Language Model for generalized Robot Manipulation

Recent progress in AI has been transformative for software. For instance, the emergence of Large Language Models (LLMs) like ChatGPT or Llama2, enabled impressive understanding and generation of natural language. Real-world embodiment is the next frontier of AI that will be transformed by these breakthroughs. Making human-robot interaction conversational and intuitive will significantly broaden the range of tasks that AI can assist with. LLMs not only generate coherent text, they build “world models” that can be applied to a wide range of economically-useful tasks. Despite steady progress, the field of robotics has been constrained by its traditional training methods: reinforcement learning (RL) and imitation learning (IL). RL is a time-consuming and resource-intensive trial-and-error process that requires an enormous number of trials to perfect tasks. On the other hand, IL, where a robot learns by observing a human instructor, needs extensive human-led training.
With PickGPT, interacting with robots has never been easier
Traditional robotic learning methods struggle to efficiently perform tasks that require a high level of adaptability, such as zero-shot learning, long-term planning, or the ability to handle novel situations. These capabilities are crucial for robots to operate in dynamic environments such as warehouses: object locations can change or new objects can appear. As such, there's an urgent need for new methods to enable more efficient and adaptable autonomous robot development.
Planning in a conversational manner
PickGPT is the world's easiest tool for instructing and programming robots. By allowing users to guide robots entirely through natural language, it prioritizes simplicity and user-friendliness. Leveraging an LLM trained on massive amounts of text data not only makes interactions easier, but also enables complex reasoning and planning. It enables the robot to understand what the user is asking for, how it relates to its visual input and how it should act.
For instance, when being asked to pack an order, it not only detects, picks and places the objects in a box, but also accounts for the physical properties of the items without being explicitly told to. This level of complex reasoning has only been made possible by leveraging large vision and language models that have been pre-trained to understand the real world.
Unlike traditional models, PickGPT uses zero-shot planning. This enables it to calculate and execute sequences of actions to achieve a target state even in complex, dynamic and unstructured environments without prior specific training. In unforeseen situations, it is able to adapt its strategy until an action is successful.
Grasping previously unseen objects
Leveraging large vision and language models trained on web-scale datasets also enables generalization to new and previously unseen objects. Previously, it was necessary to build representations for all the objects the robot could interact with after being deployed, severely limiting its adaptability. Through knowledge transfer, PickGPT can recognise and grasp an 'open-set' of objects in addition to the synthetic and real-world robotics data that it has been exposed to. It is able to locate any item in an image - a process known as 'visual grounding'. This is facilitated by a cross-attention mechanism that bridges image sections and text concepts, a core component of the transformer architecture enhancing representation learning. In PickGPT's case, this mechanism also allows it to seamlessly incorporate additional sensor data, such as depth, to more accurately predict the object's location for grasping.
How does PickGPT work?
PickGPT fuses multimodal sensor data (RGB, depth and other) and injects them into an LLM, combined with natural language instructions from a human operator or higher-level system.
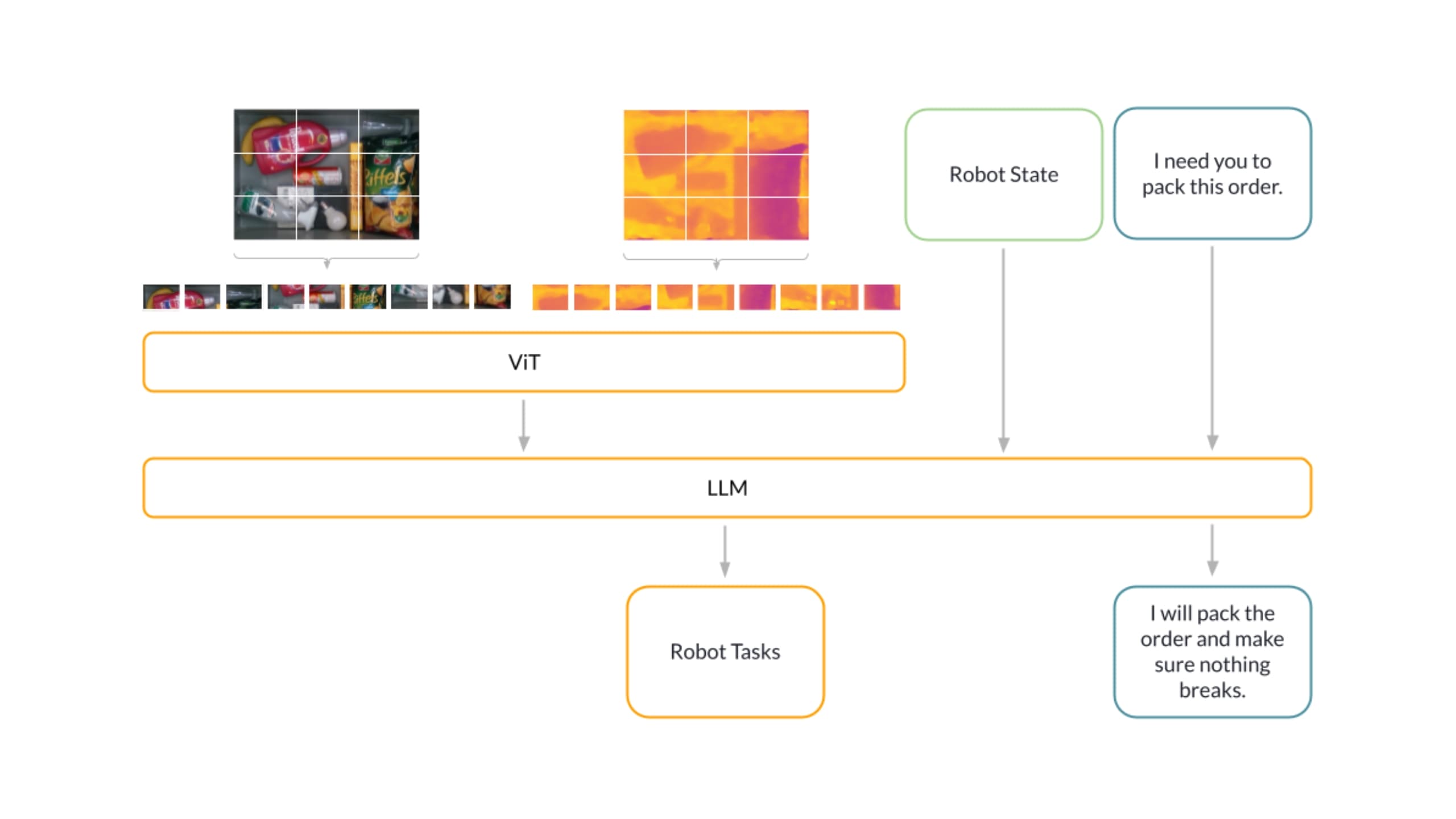
The sensor data is first divided into fixed-size patches, embedded linearly and positionally. The resulting sequence is then fed into a Vision Transformer (ViT), which performs various tasks such as segmentation, scene decomposition and sequencing. The ViT subsequently converts this into a token representation. The LLM first tokenizes and embeds input text, converting it into numerical representations. These embeddings are processed by a transformer architecture that weighs each word's contextual importance, helping the model understand the overall meaning.
Using this understanding, the model generates responses by continually predicting the next word in the sequence until a certain condition is met. PickGPT's generative output is text that can either directly solve tasks or guide low-level commands for geometrical planning or control tasks. Embedded in a control loop, PickGPT can execute decisions by a robot and adjust plans based on new observations by acting as a high-level policy that sequences and controls the low-level policy.
In addition, PickGPT includes failsafe strategies to handle unforeseen situations, enhancing its reliability and effectiveness. For instance, if a first attempt to grasp an object fails, the model doesn't simply give up. Instead, it's designed to reassess the situation, adapt its strategy, and try again. This built-in resilience and flexibility in PickGPT ensures it can effectively navigate and react to unexpected events or changes in the environment, maintaining its operational efficiency.
Conclusion
Sereact PickGPT is an industry-first, no-code, training-free software-defined robotics solution that increases the accuracy and efficiency of robotic piece picking for high-volume use cases. PickGPT combines the power of large language models – similar to those used in ChatGPT – with Sereact’s proprietary computer vision models to enable robots to pick and manipulate objects in real-world scenarios with a level of intelligence and accuracy that was previously impossible.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles