LLMs meet robotics: the next frontier

Sereact’s Vision Transformers on unknown, out-of-distribution objects
At Sereact, we tackle the age-old problem of pick and place robotics for everything from e-commerce to healthcare. Our core computer vision model is a foundational model for robotics grasping. It’s capable of predicting segmentation, 3D boxes, grasp points, and parallel jaw grasps on objects it has never encountered before.
But what if we could take it to the next level? What if we could add language to this application? Language is the ultimate interface, not just for humans but for machines as well. It’s the interface that runs the world. Being able to change the behavior of systems by telling them what to do is the endgame for automation. It’s what brings us one step closer to the dream of having a robot that can clean up a room with a simple command.

The latest YCombinator request for startups states that robotics hasn’t yet had its GPT moment, but that it’s close. I totally agree. With recent advancements in vision language models and language models, we can now guide our perception with language. At Sereact, we’ve developed PickGPT, a vision language action model capable of performing robotic tasks based on both vision and language input.
But why is this important? For one, it increases the versatility of our robotic systems. With the ability to understand natural language commands, our robots can be easily reprogrammed for different tasks without the need for extensive coding. This is especially useful in dynamic environments, such as warehouses or hospitals, where the tasks and environment may change frequently. Imagine a customer who has both open and closed boxes in their inventory. The challenge? The robot should only pick closed boxes, leaving the open ones untouched. While this might seem like a complex task, it’s a perfect example of how prompts can be used to enhance the flexibility of robotic systems.
One approach to solve this problem could be through computer vision. We could train the system to classify open boxes and discard them at picking time. Alternatively, we could compare the Region of Interest (ROI) features to distinguish between open and closed boxes. However, both methods would require substantial changes to the application, including:
- Training the grasping model specifically for this customer to exclude open boxes.
- Modifying the robot’s behavior for open boxes, which involves altering the application code and incorporating the open box class.
- Building separate versions for this customer or adding some configuration.
Instead, we opted for a more straightforward and flexible solution: using a prompt to classify open boxes. Whenever a box matching this prompt appears, the robot simply leaves it out. Changing the behavior of robotics through language doesn’t mean we have to constantly communicate with the robot. Instead, it means using language to make our robotics systems more robust and adaptable to edge cases. In this instance, we were able to quickly and efficiently address the edge case of open boxes by instructing the robot to discard them.
The ability to modify the behavior of systems through natural language offers a new level of flexibility and control to customers, allowing them to decide what their systems should do and adapt them to their specific needs. This shift in interaction empowers users, enabling them to tailor their systems to better suit their requirements without needing extensive technical knowledge or programming skills. However, the implications of this capability go beyond user experience and have profound consequences for the development process itself.
In the digital world, edge cases are relatively rare, as user interactions are typically structured and limited by the design of applications. In contrast, the real world is full of edge cases, and the ability of a system to handle these exceptions often determines its usefulness and applicability. Traditionally, addressing edge cases in robotics has required extensive coding and training, consuming significant time and resources. With the advent of large language models, this paradigm is changing. Instead of laboriously coding and training for each edge case, developers can now handle them through simple natural language prompts.
This innovation has far-reaching consequences for robotics. By enabling more use cases, unstructured scenarios, and large-scale deployments, large language models expand the applicability of robotics and unlock new opportunities. Moreover, this approach leads to a better return on investment, as resources previously dedicated to coding and training for edge cases can now be allocated elsewhere. This shift in development not only streamlines the process but also opens up new avenues for innovation in the rapidly evolving world of robotics. Moreover, language models have inherent planning capabilities. They can understand the relationships between objects, actions, and intents, and use this information to make decisions. This is crucial for complex tasks, such as sorting and packing objects, where planning and sequencing are essential. Take a look at this example: I instructed GPT-4 with the following prompt:
Imagine you are a household robot with manipulation capabilities. You are standing right next to me in the living room. I tell you: “Please bring me a beer”. Which real-world tasks do you need to perform in the right order to get me this beer.
Without any specific example prompting nor training it is able to formulate the basic commands a robot needs to fetch the beer. Not only that, it is also able to output this in PDDL (Planning Domain Definition Language) which will give us the syntactic structure to put it into commands for the robot.
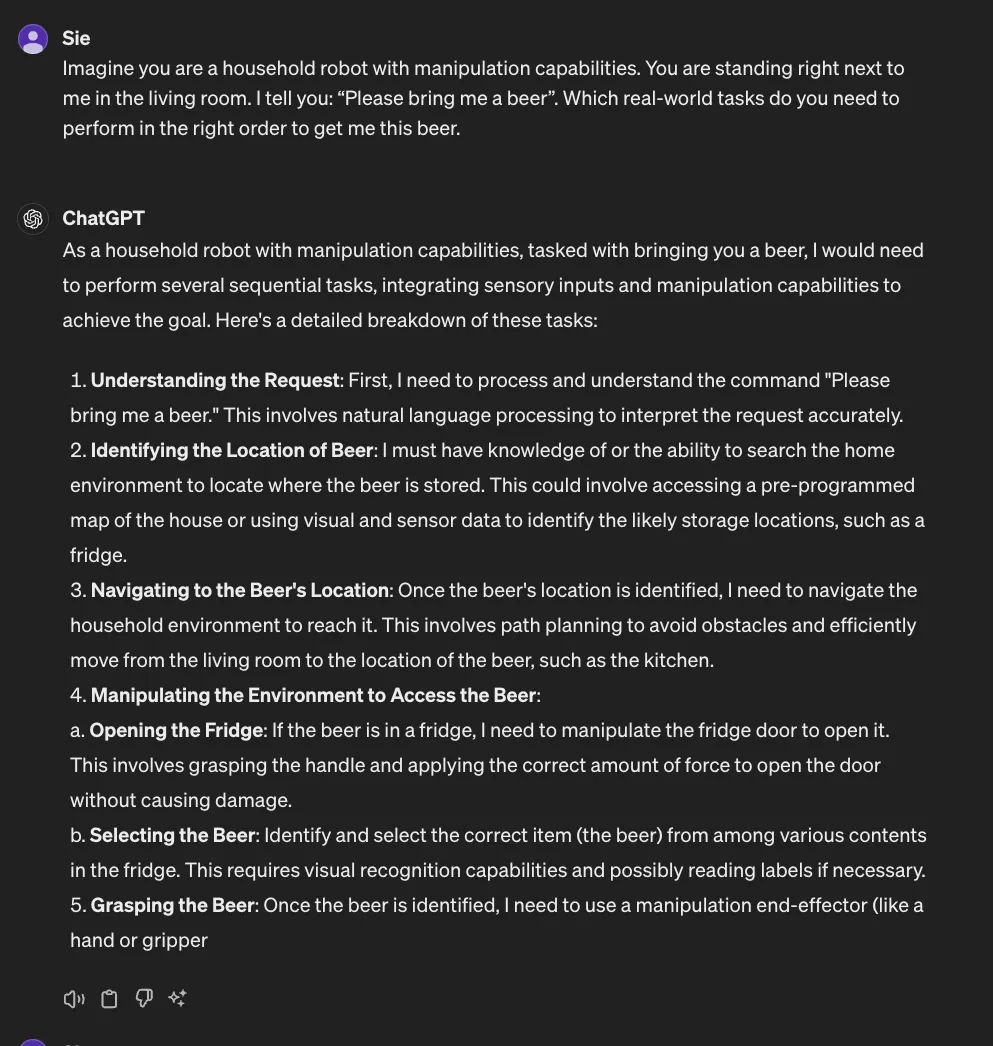
GPT-4 planning capabilities for robots
At Sereact, we’re excited about the possibilities that linguistic capabilities bring to our systems. We believe that this is the next frontier in robotics, and we’re eager to explore its potential. So, stay tuned for more updates on our work in this area and the impact that it can have on the future of automation.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles