Vision Language Models: Seeing and Understanding
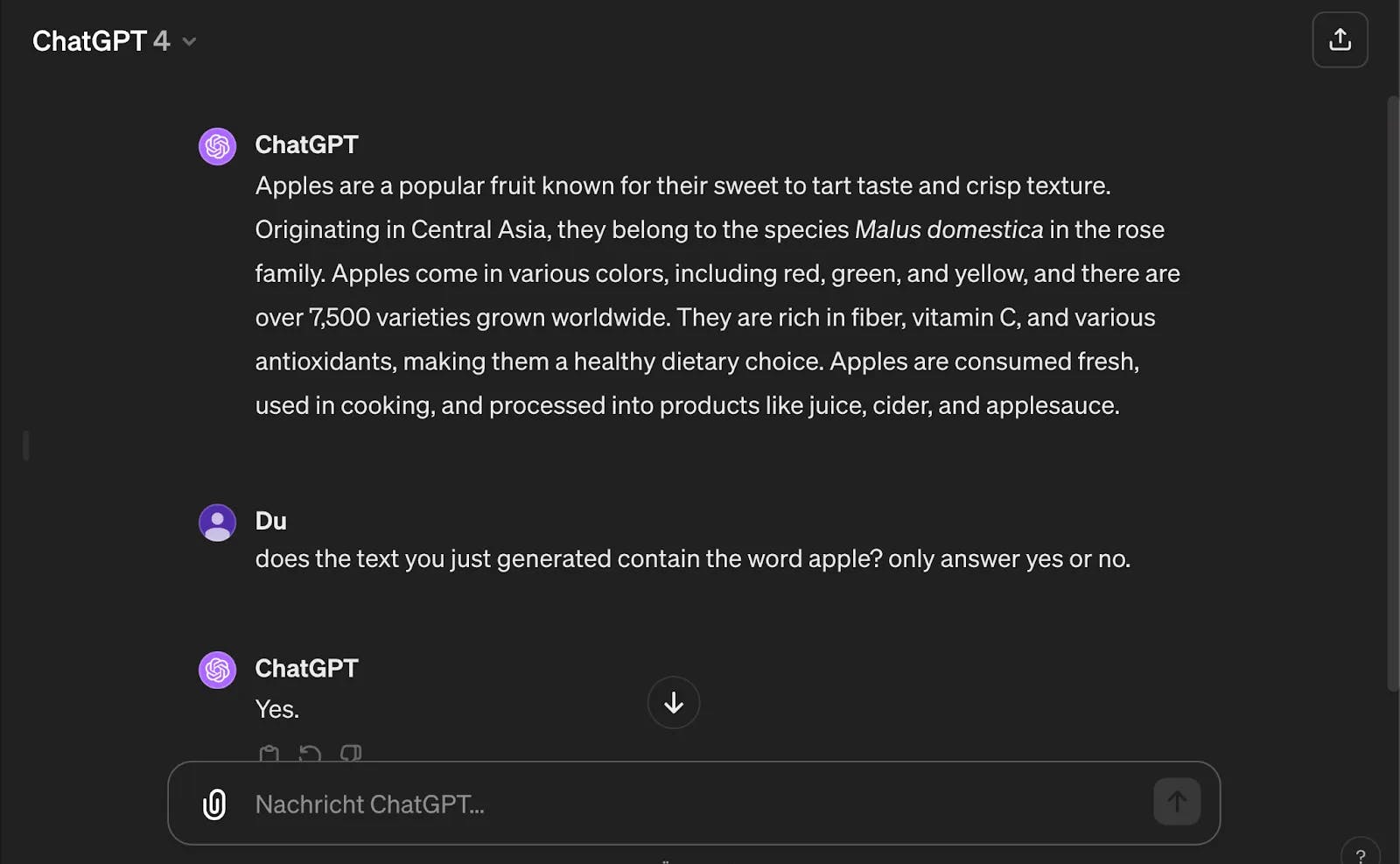
I’ve seen firsthand the incredible capabilities of today’s language models. They can generate coherent and contextually relevant text, answer questions, summarize documents, and even translate languages. These models feel like a new programming paradigm. We (and our code) can now interact with language. Perhaps more excitingly, we can also interact with images and change the perception capabilities of our models just by prompting. This blogpost will cover some basic examples of the capabilities and how VLMs conceptually work. Let’s take a look at this scenario. I asked GPT-4 to write something about apples. In the second prompt, I ask it to classify if the word apple is in the text… By itself, pretty straightforward.
In fact, you can solve this with a single line of Python.

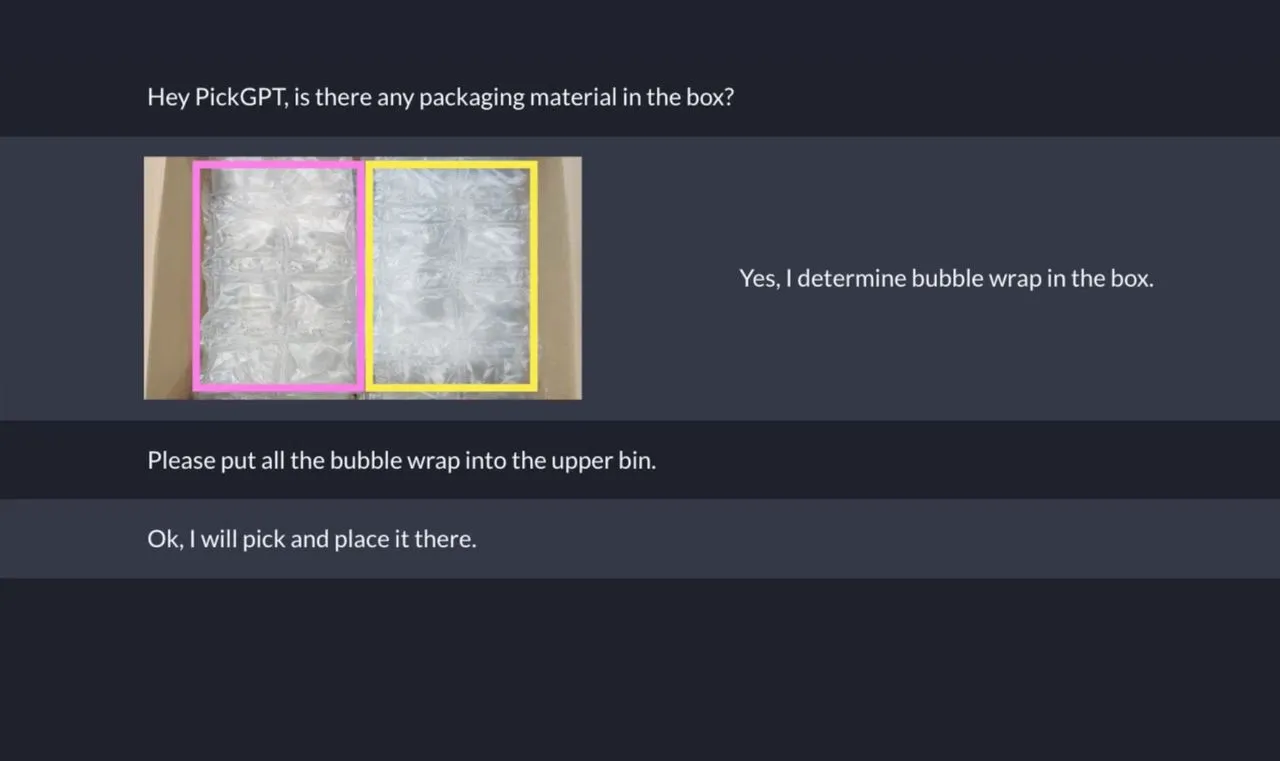
Let’s have a look at this image: some random items in a plastic box.

If I want to predict whether this image contains an apple, the best I can do with a single line of Python is a 50/50 guess…
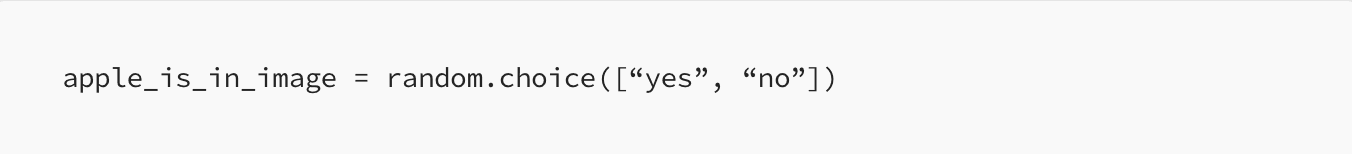
However, if I ask PickGPT (Sereact’s Vision Language Action Model) if the image contains an apple, it’s able to predict this very accurately.
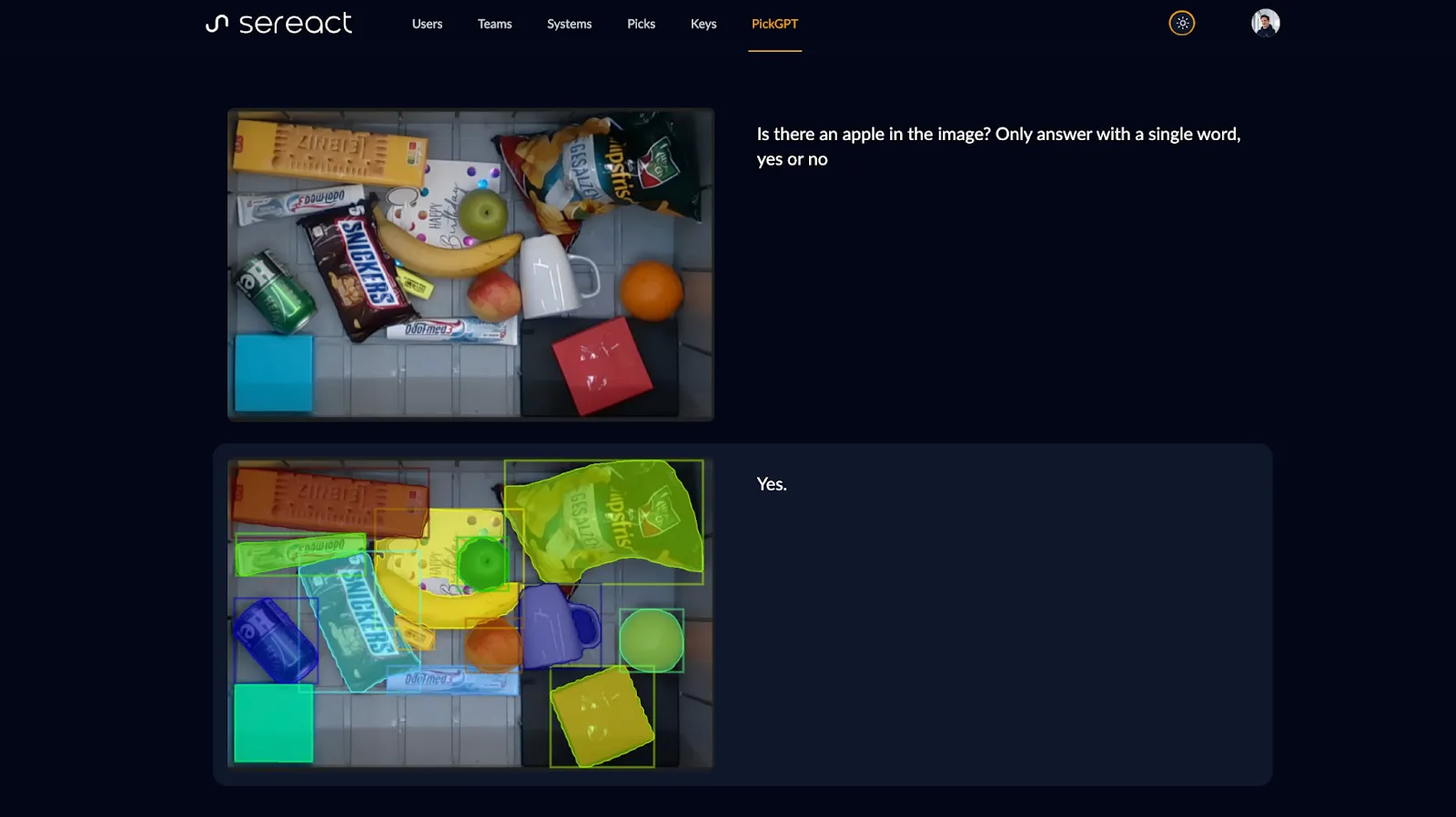
Perhaps surprisingly, this means, we can do zero-shot classification with vision language models. In fact, we are guiding the perception of our computer vision with language. In another sense we can tell it to put its attention (hehe) towards looking for apples. These VLMs, and LLMs, are in some sense trained instantly via prompting. The activations inside the network change, based on the prompt.
How does this actually work? First, we need to go back a few years. CLIP was released in 2021 by OpenAI and is essentially trained to minimize the distance between a feature embedding of an image and a feature embedding of the corresponding text.
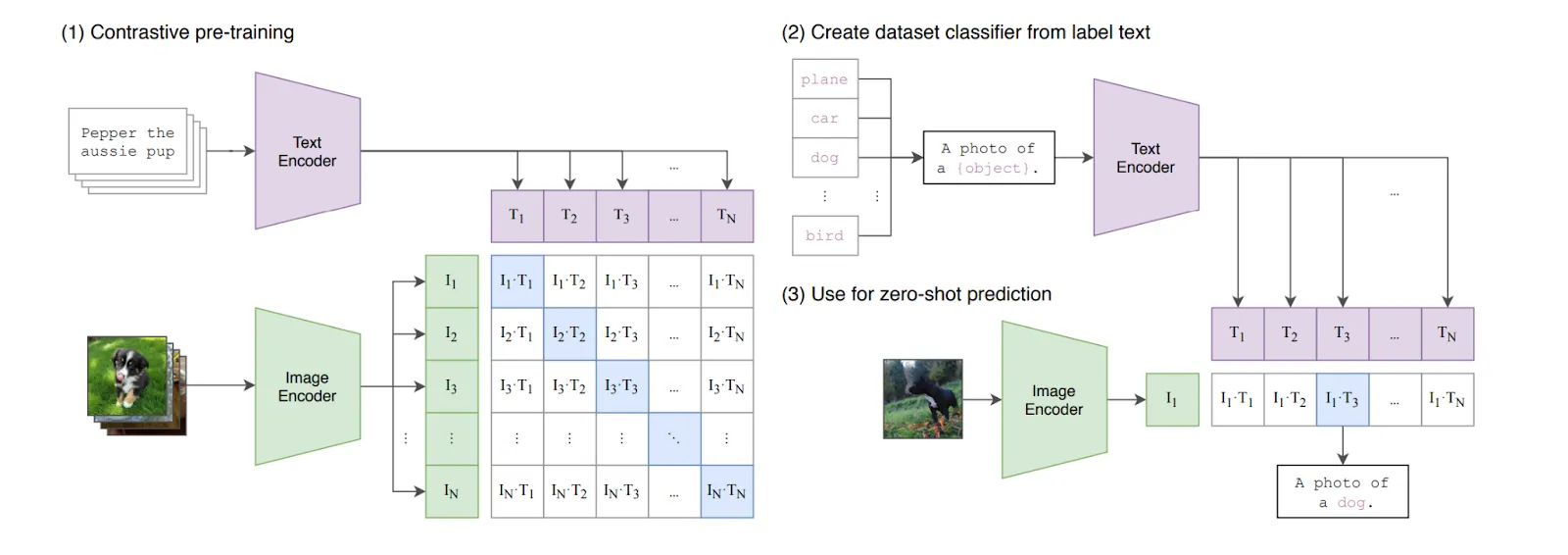
The language embedding of the text “a photo of an apple” should be close to the vision embedding of a photo of an apple. CLIP is trained on pairs of images and text captions, some matching and some non-matching. It learns to encode the image and caption into numerical representations (embeddings) such that the embeddings of a matching image-caption pair are close together (high cosine similarity), while the embeddings of non-matching pairs are far apart (low cosine similarity). This allows CLIP to effectively turn images into text-like embeddings.
Recently, LLaVa-Next, an open-source vision language model, was released. On release it was on par with GPT-4 and actually exceeded Gemini. It takes in images and text, and can assist in answering questions about the image.
This model first uses CLIP to convert the image features into a numerical embedding that a language model can understand, essentially translating the image into text-like tokens. However, since the embedding space of CLIP may vary from the expected token representations of the language model, a separate “vision language connector” component is trained. This connector aligns and maps the CLIP image embeddings to the specific token space that the language model is expecting. With this alignment step, the language model can now directly process and understand the visual information from images, enabling multimodal capabilities.
LLaVa-Next is just one of many vision language models trained for different use cases and on different datasets. But the methodology usually is always the same: bring images into a representation that a language model understands and feed this representation into a language model. This also means that we can improve our computer vision capabilities by using a bigger language model. I don’t know the internals of SORA, but the technical report suggests that video generation follows the same basic principle, while using a bigger model.
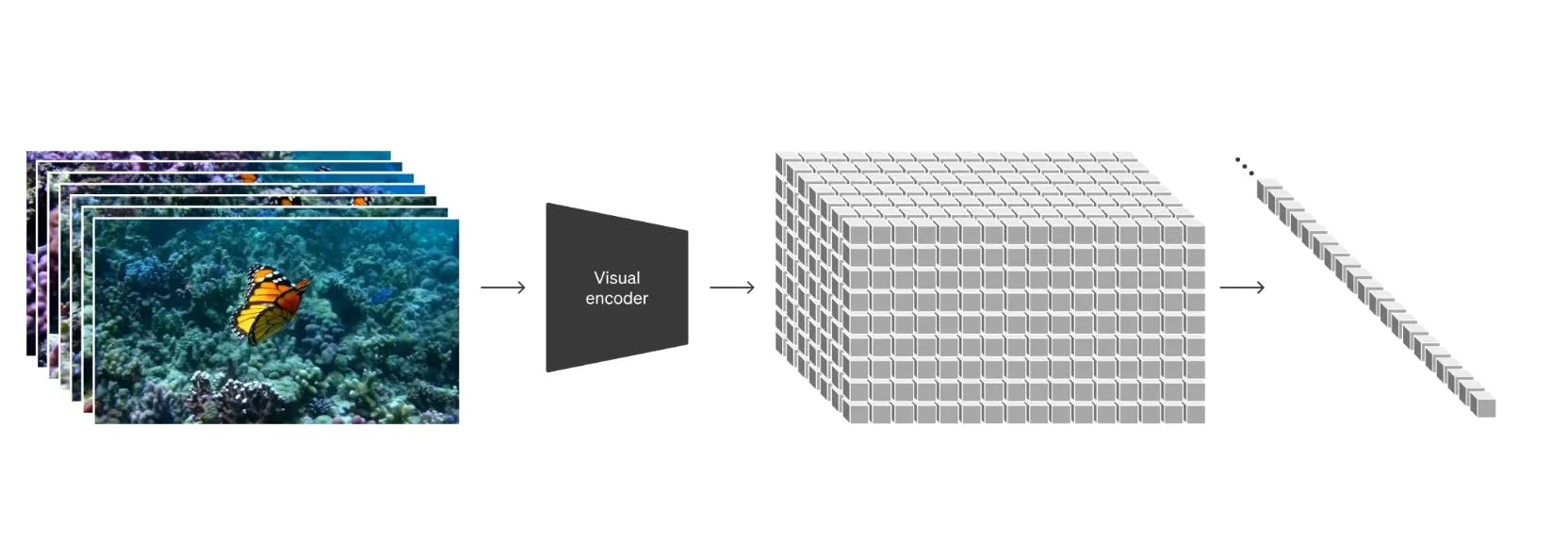
First the consecutive frames of the videos are brought into a representation a language model can understand via a visual encoder. Then this representation is fed into a language model. Of course, here the details matter since the model has to attend to the neighboring sections in the current frame and also attend to the last frame it predicted. Which is basically combining vision with the autoregressive nature of text generation. This has the same benefit of being able to just swap the LLM to a bigger one to generate better results. The report also shows the results of using “more compute”.

Of course, I’m not going to pretend that there aren’t still challenges to be addressed. As with any emerging technology, there are still plenty of kinks to work out. But as someone who’s always been more interested in getting things done than worrying about the obstacles, I’m confident that the deep learning community figures it out.
This concludes my first blogpost on vision language models. Stay tuned for more in depth discussions of vision language models. In the next post I will cover how we use Vision Language Models for Robotics at Sereact.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles