Cortex 1.5: Interactive RL Policy Patching for Real-World Robotics

Deploying Vision-Language-Action (VLA) models reveals a critical limitation: the distribution shift between static pretraining and the dynamic real world. When faced with novel configurations, even robust policies exhibit systematic failure modes. To overcome this, we propose a paradigm shift inspired by biological intelligence. Humans and animals learn through self-exploration as well as interaction with teachers. We believe that the future of robot learning is rooted in the principles of self-learning and interacting with human teachers.
Learning Through Exploration
We introduce Interactive RL Policy Patching, a distributed framework that enables self-learning from human reward and policy updates through brief human corrective interventions. We adapt online off-policy reinforcement learning to enable this method. Our approach supports rapid adaptation to new task conditions while preserving previously acquired skills, with the policy's behaviour aligning more favourably to the human preferences as well as requiring less exploration time compared to traditional approaches.
Beyond Retraining: Continuous Improvement via Policy Patching
When a policy exhibits incorrect behavior, a common approach is to collect additional data and retrain or broadly fine-tune the model. While this can correct the observed failure, it is inefficient, as it requires repeated cycles of full retraining and rollout for many rounds until all the errors are observed and the whole state-action space is well-covered. Instead, we treat policy correction as a lightweight update. Brief human guidance shows the desired behavior in the failure state, and this information is then incorporated through reinforcement learning to update the policy. This allows targeted correction of specific failure modes without retraining the entire policy.
Interactive RL Policy Patching
We present Interactive RL Policy Patching, a framework that integrates demonstration-based guidance into reinforcement learning to achieve efficient adaptation with improved generalization.
1. Foundation Model
Our Cortex model provides a strong prior, trained on hundreds of millions of real-world robot interactions. It captures general principles of industrial pick-and-place but, like any pretrained model, encounters edge cases where its learned policy is insufficient.
2. Human-Guided Demonstration
When the robot fails in a novel scenario, a human operator intervenes via teleoperation, providing a brief demonstration that resolves the specific failure case.
3. Interactive RL Rollout
Rather than training the model to minimize trajectory error against the demonstration, we use the human input to serve as guidance and shape a reward signal for off-policy reinforcement learning:
- Patch: The operator demonstrates the corrective behavior.
- Policy Update: We update the model using online off-policy reinforcement learning.
- Rollout: The robot executes the updated policy in the real environment.
- Verification: If the task succeeds, a positive reward reinforces the new behavior. (Currently, this reward is provided by the operator due to the high complexity of the tasks we are facing; we discuss future directions below.)
Figure 1: Overall System Architecture
This architecture creates a feedback loop that bypasses the sample-inefficient exploration phase of pure RL while avoiding full retraining of the policy.
Replay Memory
Training is performed on centralized GPU infrastructure, drawing from a replay buffer that aggregates three data sources:
- Offline Data: An extract of our industrial manipulation data collected from over 100 deployed robot stations, supplemented by human teleoperation recordings. This provides the base distribution for pretraining the VLA model.
- Online Data: Continuously collected rollouts from deployed policies operating in production environments. This captures distribution shift and environmental variability that offline data alone cannot represent.
- Behavioral Patch Data: Short, targeted episodes in which human operators demonstrate corrective actions in response to observed failures.
Actor-Critic Architecture
We use an actor-critic framework for policy optimization. The actor generates actions, the critic learns the expected value of a state-action pair. This design enables rapid policy updates, as the actor can incorporate corrective behaviors with relatively few gradient steps. In addition, this allows us to train the pipeline end-to-end using direct signals from the environment, bypassing the need for a complex learned reward model.
Distributed Parameter Synchronization
To propagate improvements across the deployed fleet, we maintain a distributed parameter queue. The centralized learner periodically publishes updated policy weights, which are asynchronously pulled by individual robots. When an operator provides a corrective demonstration at one site, the resulting policy update becomes available fleet-wide, amortizing the cost of each human intervention across all deployments.
Real-world Experiments
We evaluate Interactive RL Policy Patching on two manipulation tasks, comparing it against our baseline imitation learning-pretrained Cortex VLA. The first is a shoe box unboxing task, where the robot opens a shoe box, removes the packing paper and places the shoes into a separate bin. The second task involves sorting screws into a toolbox, with the robot required to place each screw into the correct organizer compartment.
Shoe Unboxing Task Patching (Paper Picking Patch)
Shoe Unboxing Task Patching (Sole Picking Patch)
Screw Sorting Task Patching (Picking Patch)
Empirically, Policy Patching suggests a reduction in both data requirements and computational overhead. Because errors are often localized to specific points in a trajectory, collecting partial episodes allows for more targeted corrections compared to full-episode data collection. We observed that the patch intervenes at the first sign of failure, effectively shortening the sequence of actions the robot needs to learn. This simplifies the problem by focusing on immediate correction rather than long-term recovery. These observations indicate that Policy Patching is a promising direction for improving policy robustness with lower data overhead.
Early Results
Early results indicate that the primary limitation of imitation learning-pretrained Cortex VLA lies not in nominal task execution, but in their inability to reliably and efficiently recover from rare or unseen failure states. Policy Patching directly targets these weaknesses by injecting human-supervised recovery trajectories at failure points, enabling the policy to learn new behavior from minimal additional data. As a result, improvements in success rate are driven largely by gains in recovery capability rather than extended exploration or longer training. The reduced episode length and rapid adaptation further suggest that Policy Patching focuses learning on high-impact state transitions, making it more efficient and more robust for real-world deployment. This also lowers the barriers to real-world training. Real-world environments are unforgiving: resets are slow, hardware is fragile, and exact state replication (crucial for methods like pairwise online RL) is often impossible. By requiring fewer rollouts and teleoperation hours to reach convergence, our method navigates these physical complexities more safely and cost-effectively than standard approaches.
Our experimental evaluation primarily focuses on the trade-offs between Policy Patching and full policy retraining, demonstrating clear advantages in data efficiency and performance robustness. To provide a broader context, we are also in the process of benchmarking these methods against pure reinforcement-learning-based self-exploration approaches.
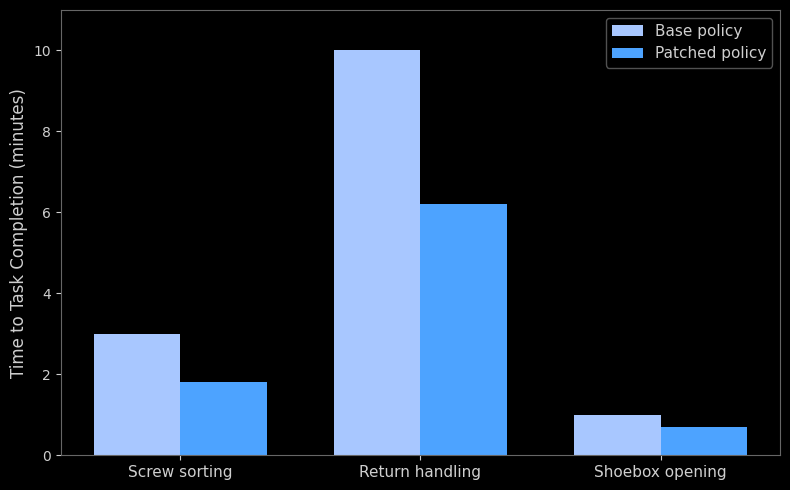
Figure 2: Effect of Policy Patching on Episode Length Across Tasks
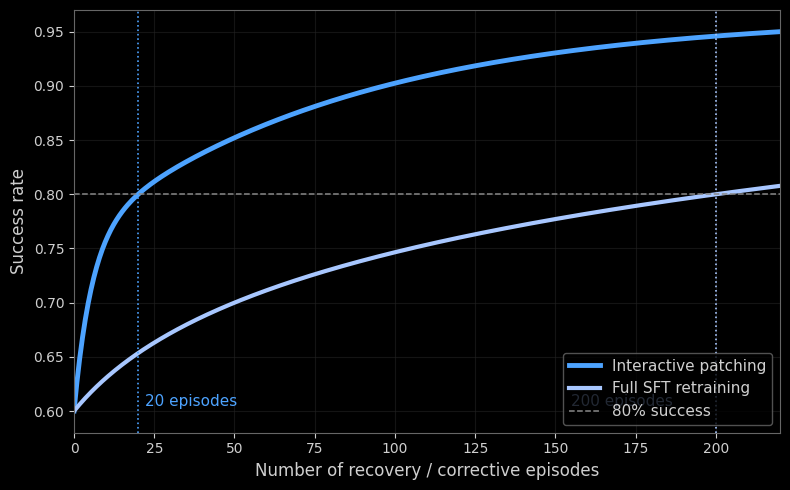
Figure 3: Sample Efficiency of Interactive Policy Patching Compared to Full SFT Retraining
Future Directions
Policy patching enables targeted corrections without retraining entire policies. By initiating episodes from specific failure states and providing focused demonstrations, we can address failure modes with minimal data, avoiding the cost of full retraining cycles. Additionally our method is a step towards fleet learning of multiple tasks and results in policies that are more goal oriented than pure imitation learning policies.
Regardless of how foundation models or data collection methods advance, sample-efficient behavior correction will remain a core challenge in deploying robotic systems at scale. Interactive learning approaches like the one described here offer a practical path toward continuous improvement in deployed fleets, where retraining from scratch is often infeasible. We are looking forward to sharing detailed results in the upcoming paper.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles