Cortex 1.6: Learning From the Way Things Unfold

Dense Reward Learning from Real-World Robotic Deployments
Introduction
Consider a warehouse robot picking thousands of items per hour. A grasp that slowly loses vacuum, triggers retries, and finally drops the object contains rich learning signal-but most learning systems only observe a single bit: failure.
In physical manipulation, success and failure are not discrete events but processes with internal structure, unfolding gradually through interaction forces, timing constraints, and control stability. Our industrial robotic deployments generate continuous streams of multimodal operational data, yet nearly all of this signal is discarded by learning pipelines that reduce execution to a single terminal outcome. This mismatch between the richness of real-world execution and the sparsity of learning feedback represents a central bottleneck for robotic learning in production.
Cortex 1.6 introduces the Process-Reward Operator (PRO), a learned reward model designed to extract dense, continuous learning signals directly from real-world robotic operation. Rather than relying on hand-engineered rewards or simulation-specific metrics, PRO converts operational signals observed during deployment into a unified notion of progress, completion likelihood, and risk. This enables reinforcement learning and policy improvement while robots are actively delivering customer value.
Rich telemetry from our industrial robots to train PRO (joint positions, forces/tactiles, SKU identifiers, WMS metadata, task prompts, and status flags).
Motivation: The Limits of Sparse Rewards in Physical AI
Vision-Language-Action (VLA) models have shown strong performance in robotic manipulation through large-scale pretraining and supervised fine-tuning. Yet their learning remains fundamentally limited by sparse, delayed feedback, typically reduced to a binary notion of success or failure. In industrial deployments, learning is still driven by terminal outcomes, even though the richest supervision arises during execution.
This outcome-centric learning makes it difficult to identify which parts of an execution contributed to success or failure. In real robotic systems, failures rarely occur instantly; unstable grasps, marginal suction, repeated retries, or small misalignments that only later lead to drops, jams or aborted tasks. Traditional reinforcement learning formulations struggle to exploit this structure, as they depend on manually designed reward functions or terminal signals that arrive long after the underlying cause.
Cortex 1.5 demonstrated that policies can be efficiently corrected through human-guided policy patching, enabling rapid recovery from rare failure states. However, this approach requires explicit human intervention, leaving large portions of routine execution-especially fragile but ultimately successful behaviour-unused for learning.
Industrial robots already generate rich telemetry on forces, stability, timing, and recovery actions, but sparse outcome-based learning cannot leverage this information. As a result, algorithms cannot distinguish robust executions from fragile ones when both end with the same terminal label, leaving most operational data disconnected from policy improvement.
The central hypothesis behind PRO is that this gap can be closed by learning rewards directly from execution. By modeling execution quality instead of binary outcomes, PRO provides dense feedback aligned with real operational objectives, as illustrated in the video, and enables more effective credit assignment in long-horizon robotic tasks.
The Process-Reward Operator
PRO is a learned function that evaluates ongoing robotic execution by mapping intermediate robot states and short execution segments to three signals:
- Progress – whether execution is moving closer to or farther from successful task completion.
- Completion Likelihood – the probability that the current trajectory will succeed.
- Risk – the likelihood of instability or failure (e.g., slips, drops, jams).
Importantly, PRO is not task-specific in the classical sense. It is goal-conditioned and trained across deployments, object types, and operational contexts, allowing generalisation across tasks while remaining grounded in physical execution.
PRO Modules explained
PRO operates on multimodal observations from real-world execution. At time , the observation consists of:
capturing complementary aspects of the robot's state:
- - the executed action, allowing PRO to evaluate action quality, model action-conditioned progress and risk, and distinguish whether changes in execution state are attributable to control decisions versus environment dynamics.
- - visual observations from Cortex visual encoder.
- - robot proprioception, including joint states, TCP pose, and end-effector status.
- - operational force and interaction telemetry, such as vacuum pressure margins, force–torque statistics, contact forces, and slip indicators, which directly reflect physical stability and interaction quality.
- - a goal-conditioning prompt, represented as a text embedding and optionally augmented with site- or deployment-specific context.
These inputs provide continuous signals about execution quality, enabling PRO to reason over short temporal windows and detect trends like degrading grasps or growing instability-information unavailable to sparse-reward methods.
Each modality is mapped into a latent representation using modality-specific encoders. Executed actions are encoded separately allowing PRO to condition progress, risk, and termination predictions explicitly on the applied control commands and to distinguish action-induced effects from environment dynamics. Visual observations are projected through a small adapter on top of the Cortex visual encoder. Robot state and telemetry are encoded via a lightweight multilayer perceptron with normalisation layers to ensure stability across heterogeneous signal scales. Goal and site conditioning use Cortex language encoder to maintain semantic alignment. These encoders normalize heterogeneous sensory streams into a common latent space while preserving modality-specific structure. Since PRO functions as a critic rather than a policy, encoder capacity is intentionally limited to improve generalization across deployments.
The encoded features are fused using a shared VLA backbone to produce a unified representation of the current execution state. Visual, proprioceptive, telemetry, and goal information are fused into a single latent token, after which the action embedding is concatenated. This creates a compact state representation that reflects both the environment and the robot's recent control decisions. The resulting fused token serves as input to the temporal reasoning model.
PRO evaluates execution over short time windows rather than single timesteps. A temporal model processes a sequence of recent states to produce a temporal latent representation that captures both the current situation and recent trends. This is essential for real-world manipulation, where failures typically emerge gradually rather than instantly. Subtle patterns-such as declining vacuum pressure, growing pose error, or increasing contact instability-often signal problems long before a terminal failure occurs. These dynamics are invisible to single-step evaluators but become clear when modeled over time. The resulting temporal latent serves as a compact summary of execution quality and forms the basis for PRO's predictions of progress, completion likelihood, and risk.
From the temporal latent , PRO produces three complementary outputs. All heads share the same temporal backbone but are trained with distinct supervision signals.
Progress
The progress head models completion potential-how close the system is to successful task completion-rather than instantaneous reward. It predicts a value function over execution states, from which dense progress signals are derived.
The progress head predicts a value
where is an implicit reward derived from execution outcomes and telemetry (e.g., success, retries, safety events).
Dense progress is defined as the change in value: . Positive values indicate movement toward successful completion; negative values indicate degradation.
Termination
A termination head predicts the probability of episode termination at timestep :
and optionally the conditional probability of success given termination:
Risk
The risk head predicts the probability that a failure or recovery-triggering event will occur within a fixed future horizon :
In the multi-class setting, the head outputs a categorical distribution over predefined failure modes.
The outputs of PRO are consumed by downstream execution and learning mechanisms without modifying the underlying VLA policy. At inference time, it evaluates candidate actions by estimating their expected cumulative progress and risk:
where controls risk sensitivity. Termination probabilities are used to gate retries and prevent pathological execution loops. For learning, PRO provides a dense reward signal derived from real-world execution. Once trained, its progress and risk outputs are treated as reward signals for policy optimization. Offline reinforcement learning uses these signals to learn from logged trajectories, while online fine-tuning uses PRO outputs under additional safety and regression constraints to ensure conservative updates during deployment. PRO further provides a unified, interpretable evaluation metric across sites and deployments, enabling systematic analysis of execution quality and failure modes.
Integration with Reinforcement Learning
PRO serves as a shared reward backbone for multiple learning and control pathways:
- Offline reinforcement learning, where dense progress signals enable learning from logged trajectories that would otherwise provide only sparse supervision.
- Online reinforcement learning, enabling continuous policy improvement driven by real-time feedback, without waiting for task termination.
- Inference-time action selection, where candidate actions or action chunks are ranked based on expected progress and risk.
- Evaluation and monitoring, providing a unified, quantitative measure of execution quality across sites and deployments.
Crucially, PRO does not replace the underlying VLA policy. Instead, it augments it by providing a physically grounded learning signal that reflects real operational success criteria.
Learning from Real-World Operation
PRO is trained entirely from real deployment data, without reliance on simulation-generated rewards or synthetic annotations. Training signals are derived from comparisons between trajectories and outcomes observed in production:
- Successful versus failed executions
- Trajectories with low versus high retry counts
- Efficient executions versus those with cycle-time inflation
- Stable grasps versus those requiring recovery
By learning from these comparisons, PRO acquires an implicit understanding of which intermediate states and transitions are predictive of desirable outcomes. This allows it to assign dense reward signals at every stage of execution, even when the final outcome has not yet occurred.
Relationship to the Real-World Learning Loop
The Real-World Learning Loop relies on the idea that deployed robots should improve continuously while performing useful work. PRO enables this loop by ensuring that every second of operation contributes learning signal, not only rare successes or failures. As fleet size grows, PRO benefits from increased diversity of states and execution contexts, leading to compounding improvements in reward quality and downstream policy performance.
This creates a positive feedback cycle: better reward models enable more efficient learning, which improves execution quality, which in turn generates cleaner and more informative data for further training.
Results
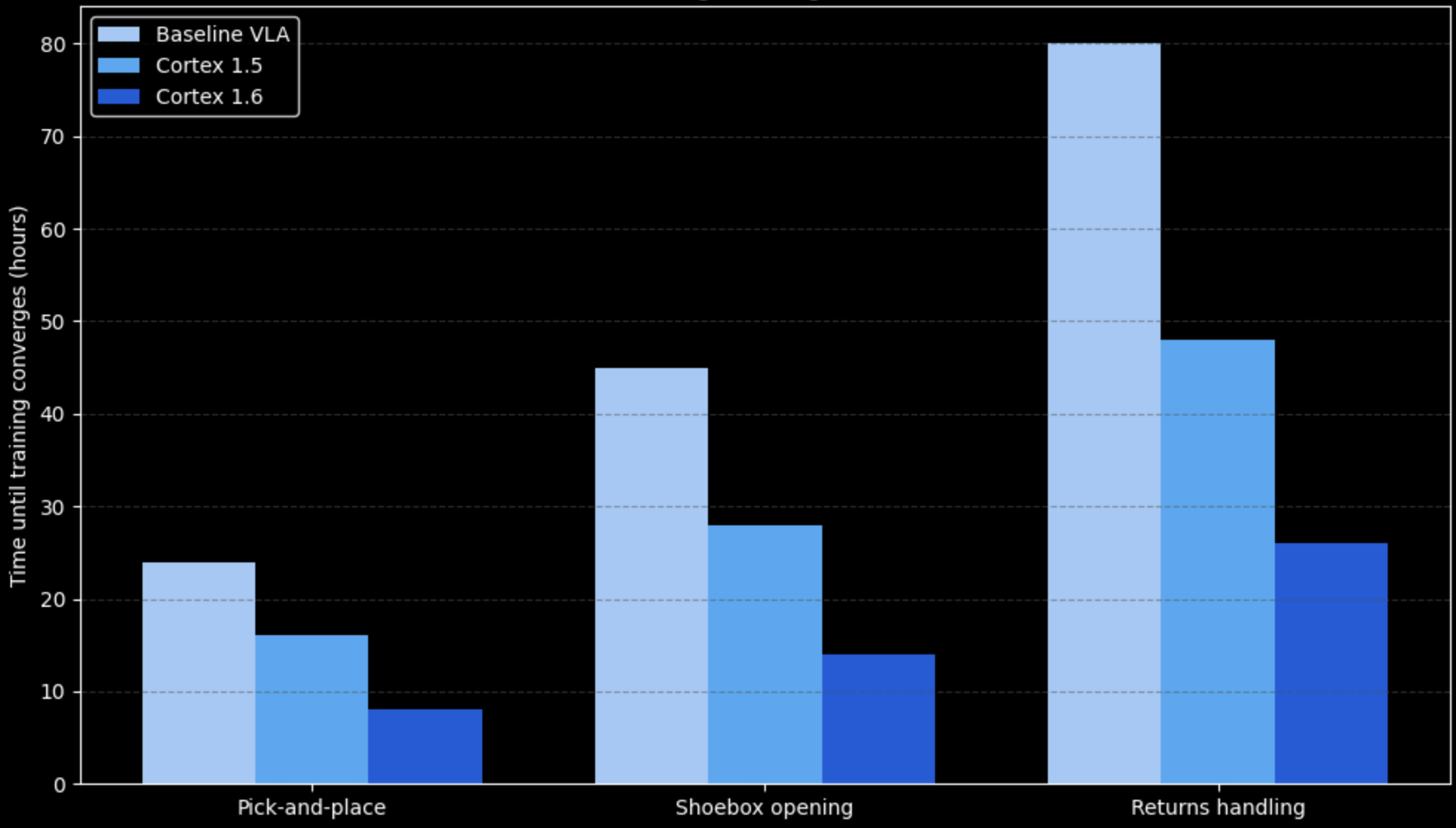
We evaluate Cortex 1.6 on pick-and-place, shoebox opening, and returns handling workflows using data collected entirely from live production deployments. All metrics are computed directly from operational telemetry, without simulated environments or handcrafted task rewards. Performance is compared against (i) a baseline imitation-learning VLA policy, (ii) Cortex 1.5, which relies on binary success signals and human-triggered policy patching, and (iii) Cortex 1.6, which learns from dense scalar rewards extracted from execution.
Task Performance and Efficiency
Across all tasks, Cortex 1.6 demonstrates higher success rates than prior models. The baseline VLA achieves a success rate of approximately 80–82%. Cortex 1.5 improves success to ~95%, primarily by learning recovery behaviors after failures. Cortex 1.6 further improves success to ~98%, demonstrating more reliable manipulation and fewer unrecovered failure modes.
Dense rewards from PRO enable faster learning. The time required for policies to converge on each task is:
Across all workflows, Cortex 1.6 reduces convergence time by roughly 2× relative to Cortex 1.5 and by more than 3× compared to the baseline.
Recovery and Retry Behavior
Improvements in success are driven by better recovery and early intervention:
- Recovery success following an initial failure increases from ~45% (baseline) to ~65% (Cortex 1.5) and ~80% (Cortex 1.6).
- Average retries per episode decrease by 30–50% across tasks after training with PRO.
Learning Efficiency
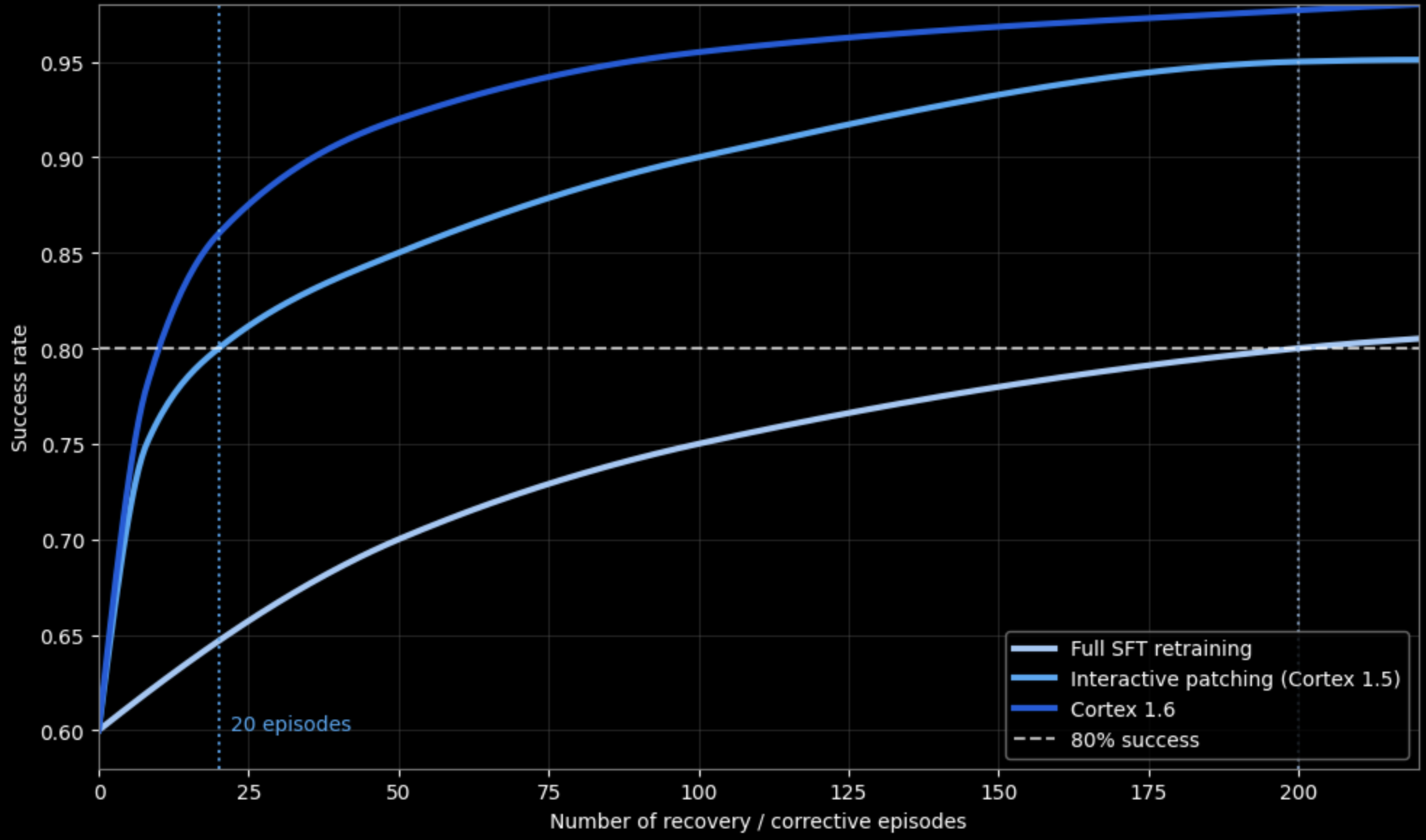
Figure 3 shows that PRO achieves comparable or better performance than full SFT retraining with 4–5× fewer corrective episodes. Using dense progress and risk signals from PRO allows reinforcement learning updates to focus on high-impact execution segments rather than entire trajectories.
Compared to Cortex 1.5, which depends on explicit human intervention to trigger learning, Cortex 1.6 continues to improve autonomously during deployment. Dense reward signals extracted from routine operation enable learning even from successful but fragile executions that would otherwise provide no feedback.
Summary
Overall, Cortex 1.6 improves:
- Success rate: +6–9% over Cortex 1.5 and 15–25% over baseline VLA
- Recovery rate: ~1.7× over baseline
- Training convergence time: ~2× faster than Cortex 1.5 and ~3× faster than baseline VLA
These results demonstrate that learning dense rewards directly from real-world executions enables more robust, efficient, and scalable improvement than binary feedback or episodic human intervention alone.
Discussion
The Process-Reward Operator reframes reinforcement learning in physical systems from a problem of reward engineering to one of reward learning. By grounding rewards in operational signals rather than abstract task definitions, PRO aligns learning objectives with real industrial performance metrics such as reliability, efficiency, and robustness.
While Cortex 1.6 does not solve all challenges in robotic learning, it addresses a central bottleneck in scaling real-world reinforcement learning: the absence of dense, trustworthy feedback. As such, it provides a foundation upon which more advanced learning mechanisms- such as world-model-based planning or hierarchical policy learning-can be built.
Conclusion
Cortex 1.6 introduces the Process-Reward Operator as a principled approach to dense reward learning in real-world robotic systems. By extracting continuous progress and risk signals from operational data, PRO enables reinforcement learning that is scalable, deployment-friendly, and tightly coupled to real physical performance. This represents a step toward robotic systems that not only act in the world, but systematically improve through it.
We are also hiring! If you'd be interested in joining us please get in touch.
For researchers interested in our work, collaborations, or other queries, please write to research@sereact.ai.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles