Cortex 2.0: Planning Before Acting

Cortex 2.0
Cortex 2.0 at a glance
- Foresight. Cortex 2.0 adds planning to manipulation by predicting future outcomes before committing best one to motion.
- Fewer costly failures. Those futures are scored for progress, stability, and efficiency, so the robot avoids bad branches before they turn into retries or recoveries.
- Video-first world modeling. The world model learns predictive dynamics in visual latent space, while action generation remains in the execution stack.
Introduction
Cortex 2.0 extends our original Cortex architecture by introducing a world model into the learning loop. Rather than replacing the existing VLA, the world model complements it, enabling reasoning and evaluation over future outcomes.
Robotic manipulation in real-world industrial environments presents a distinct set of challenges: actions are irreversible, failures are costly, and the consequences of decisions often unfold over long horizons. While recent Vision–Language–Action (VLA) models have demonstrated impressive generalization and flexibility, they remain fundamentally reactive systems, optimized to select the next action given the current observation.
In complex tasks like returns handling, the robot often faces cluttered bins, unknown object poses, and long-horizon failure modes like gradual slip, jams, or collisions that only emerge after several steps. Cortex 2.0 addresses this by shifting from try-and-see control to plan-and-try. From the current state, it generates a variable set of candidate future trajectories in visual latent space, then scores each candidate according to expected success and efficiency. The score is fed forward as advantage signal guiding action generation, biasing the policy toward motions associated with higher-quality predicted outcomes.
We train our world model in visual space because the data is cheap and far more abundant: unlimited video on the internet, and in deployment cameras get a free multiplier: one robot produces one action stream, but 10 cameras can yield ~10× more observational training signal for world models.
This helps the world model learn the underlying semantics of the physical world: joint commands are numbers with weak semantic structure and strong embodiment dependence, while pixels encode rich, transferable regularities about objects, contact, and motion.
From Reactive Policies to Physical Reasoning
Cortex 1.0 is centered around a Mixture-of-Experts (MoE) VLA stack that turns multi-modal perception, RGB, depth/3D geometry, proprioception, and task context, into a control signal. A VLM/MoE layer first produces a high-level, task-conditioned decision state (e.g., subgoal structure and grounded constraints), and the VLA then combines this context with the current observation to emit action chunks that route into embodiment-specific low-level controllers. This design generalizes across tasks and robots, but it remains fundamentally reactive: decisions are optimized for the next action given the current state, without explicitly evaluating potential futures.
Cortex 2.0 introduces a separation between planning and execution. The world model operates in latent space to plan future observations: given the current robot and environment state, it rolls out candidate future states of the environment. These candidates are evaluated by our PRO module, that assigns a score for each candidate. We use this score as an advantage indicator for downstream control. The VLA is conditioned on the top-scored rollout and its associated advantage score. The world model provides visual foresight, PRO supplies an advantage signal over candidate futures, and the VLA translates this foresight into robust low-level actions.
Architecture Overview
Cortex 2.0 extends the original execution architecture of our previous model with a complementary planning module. At a high level, the current observation is encoded into a latent state . A MoE reasoning module produces structured task context , our world model then predicts future observations, planned rollouts over a predefined horizon. The outcome heads (PRO module) score these planned futures and select the most promising candidate, which is then realized by the VLA and executed on the robot.
Given the current observation , including visual input, robot proprioceptive state, tactile signals, and task instruction, we first encode it into a compact latent representation .
On top of , a Mixture-of-Experts (MoE) module produces a structured reasoning state
is a learned task-conditioned embedding that mediates between perception, planning, and control.
It encodes a subgoal-level decomposition of the task and grounding variables that align language with scene entities and constraints (objects, spatial relations, contact priors). This representation steers the world model toward task-relevant futures and the execution stack toward realizing the selected future as action.
Conditioned on the current observation and output of the VLM, our world model predicts future observation latents over a horizon :
By sampling different initial conditions from the noise prior, the flow-matching world model generates multiple candidate rollouts from the same input state. This also allows us to control the granularity of the generated latents, such as the number of denoising iterations or number of candidate rollouts to trade off inference speed vs planning capability.
Planning is only useful if evaluable. Cortex 1.6 introduced the Process-Reward Operator (PRO) as a dense success/termination signal computed over executed trajectories. Cortex 2.0 lifts this idea into the planning loop: PRO heads score planned rollouts, enabling the system to prefer stable, goal-directed futures while avoiding high-risk ones.
For each candidate rollout , we apply our lightweight prediction heads (PRO) that estimate decision-relevant quantities such as:
- predicted progress ,
- predicted risk ,
- termination likelihood (outcome-aware).
We aggregate these predictions into a single rollout score
and select the best planned rollout via
We convert this score into an advantage indicator and pass it to our VLA.
The VLA conditions on the selected rollout and its advantage indicator to produce the executable action chunk required by the low-level control.
Where is the binarized advantage, for which we use the output from the PRO module as the proxy, to condition the action of the VLA. During training, the advantage signal is used to condition the VLA, teaching the policy to associate higher-quality predicted outcomes with the actions that realize them. At inference time, this signal is fixed to always reflect a favorable outcome, biasing the VLA to generate actions that best realize the highest-scoring predicted future given the current state.
Across single-arm pick-and-place, dual-arm pick-and-place, towel folding, and returns handling, Cortex 2.0 runs the same loop: generate visual-latent rollouts, score them for stability/risk/efficiency, and commit only to the best-scored trajectory. This breaks the common reactive pattern where a VLA repeats the same move after a miss—planning filters out bad futures first, then executes the most promising branch.
Because Cortex 2.0 evaluates plans in visual space, its planning generalizes across tasks and robot embodiments. Learning and transferring plans directly in action space is much harder, since action commands depend on a robot's specific kinematics and controllers; the same “good” behavior can require very different joint motions on different robots.
Early Results
We evaluate Cortex against state-of-the-art open-source visuomotor policies on a bimanual manipulation platform with dual UR5e arms. Three tasks of increasing complexity test performance across diverse manipulation primitives.

Shoebox
Multi-step sequential manipulation: open box lid, remove packing paper, and extract shoes into bins.

Sorting Screws
Fine-grained grasping of small, reflective metal screws and placement into correct toolbox compartments.

Sorting Items & Trash
Category-based sorting from cluttered bins, distinguishing everyday items from trash under varied conditions.
Planning budget
A key advantage of Cortex 2.0 is that we can dial the amount of planning per decision by changing , the number of imagined future rollouts sampled and scored before committing to an action.
Success rate (left axis) rises as increases, while time per step (right axis) also increases—capturing the central design trade-off in Cortex 2.0: more foresight yields better decisions, at higher compute/latency cost. For the task evaluations below, we fix a low-latency setting of K=2. Because planning runs in visual latent space, we can adjust planning compute through (i) and (ii) rollout quality (e.g., denoising steps), choosing higher budgets for costly failure modes (e.g., packing) and lower budgets when recovery is cheap (e.g., regrasping).
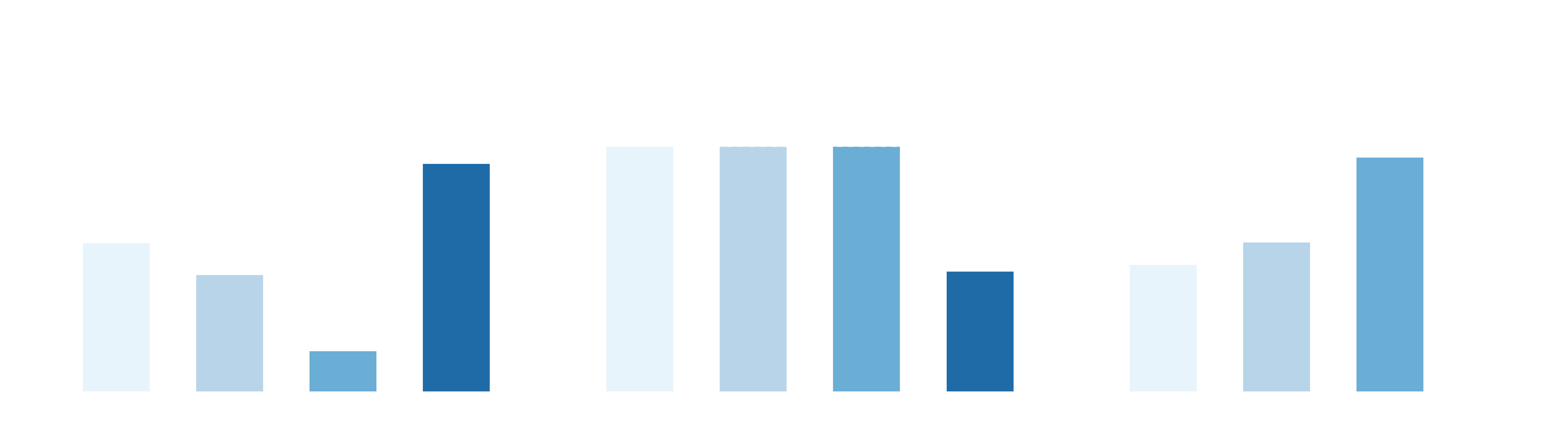
Shoebox (long-horizon sequential task)
Cortex 2.0 achieves highest success rate while also being significantly faster than baseline policies—and it completes rollouts without human interventions. Baselines either slow down due to repeated retries and late-stage deadlocks, or fail to complete the full sequence reliably.
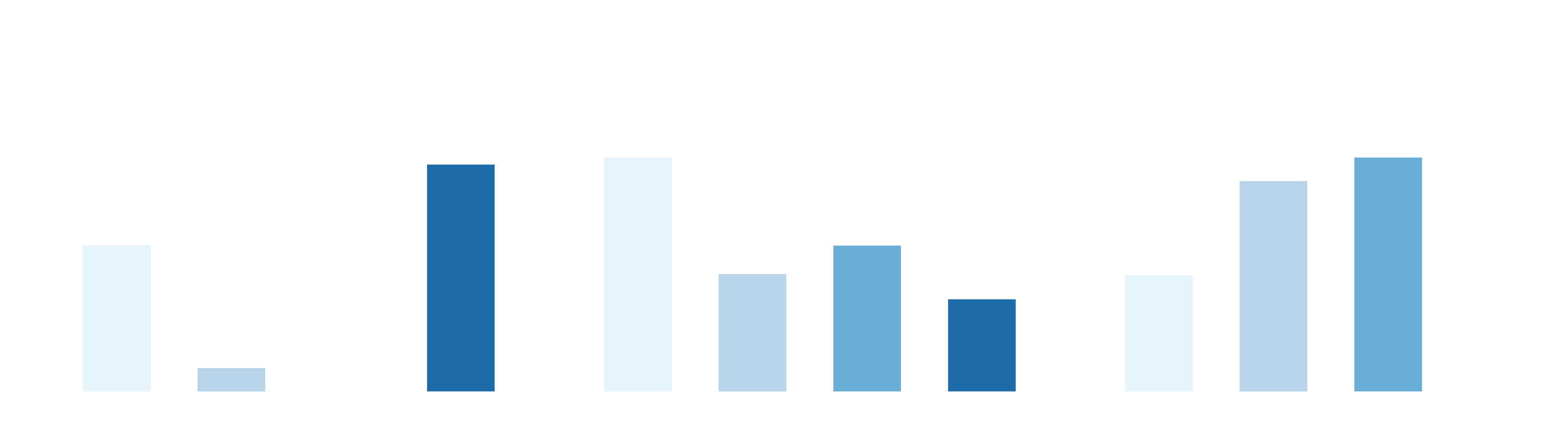
Sorting Screws (fine-grained precision)
Cortex 2.0 reaches near-perfect per-operation success on small, reflective screws, with the shortest average completion time and without requiring human intervention. Baselines struggle with accurate grasps and placement, leading to drops, misplacements, and periodic deadlocks that require intervention.
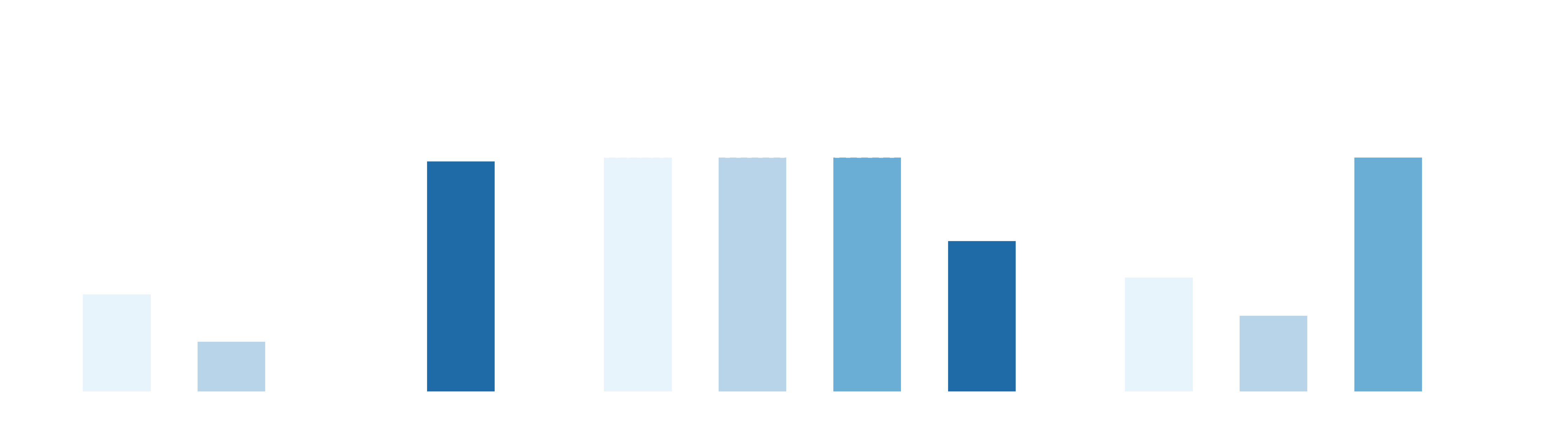
Sorting Items & Trash (cluttered repeated pick-and-place)
Cortex 2.0 achieves the highest per-object success while maintaining the best throughput, completing rollouts end-to-end without human intervention. Baselines require interventions to finish and often slow down from repeated local replanning around failed grasps, frequently reaching the runtime limit without fully completing the task.
Where we are today
We are currently training Cortex 2.0 on an increasing volume of our real-world data. The initial focus is to validate the planning loop on a narrow set of high-impact workflows, beginning with tasks inside returns handling, where long-horizon failures are common and where better foresight directly reduces operational cost. While continuing to expand use cases and tasks, we can already observe great impact of incorporating potential future outcomes into VLA policies.
Towards in-context learning
Making the policy video aware and training a world model in conjunction with policy training is a step towards in-context learning for robotics: given a sequence of demonstrations in form of a video, the robot can execute these exact steps without re-training. Today's LLMs exhibit in-context learning capabilities in many applications: agents can be conditioned to execute certain tasks just by language. We are working towards similar capabilities for robots to unlock generalization for physical AI.
Cortex 2.0 in Action
Across these four tasks, the baseline policy often gets trapped in a loop: it misses once, retries the same motion, and compounds the failure. With Cortex 2.0, the robot evaluates a few futures outcomes first and commits to the option that stays stable—so the same setups complete smoothly instead of spiraling into recovery.
Return Handling at Active Ants
Parcel Handling
Item Handling & Dispatch
Our world model helps by planning safe box opening and sensible sequencing to efficiently pick the item and avoid snags or occlusions. It also predicts which bin placement trajectory will lead to the most stable final state, reducing misplacements and the need for downstream recovery.
Kitting at Deltilog
Item Picking
Box Filling (Dual-Arm)
Box Filling (Dual-Arm)
In picking, a miss is usually just a regrasp—recovery is cheap. In box filling, small errors compound: a slightly off approach can trigger collisions with the box walls or other items, cause snags, or create damage that's costly to undo. That's why we spend more planning budget (higher k) during packing: we're not only looking for a successful placement, but the safest one. PRO-style outcome heads score risk continuously—penalizing futures with high-speed contact, compression, edge impacts, or surface scraping—even if the item still ends up in the box.
Parcel Closing at Arvato
Manual Process
Automated (Dual-Arm)
Our world model helps by predicting how the carton sheet and the items will move and settle during placement, so the robot can choose an order and alignment that keeps everything flat and ready to close the parcel.
Returns Putaway at Radial
Manual Process
Automated (Dual-Arm)
Automated (Dual-Arm)
This workflow benefits from lookahead because putaway is a tightly timed handoff: planning helps keep the scan readable while avoiding arm–arm and bin-edge interference. It also favors placements that settle stably (no snagging, rebound, or re-occlusion), reducing downstream retries in high-throughput sorting.
We are also hiring! If you'd be interested in joining us please get in touch.
For researchers interested in our work, collaborations, or other queries, please write to research@sereact.ai.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles