The Real-World Learning Loop

A different starting point for robotics intelligence
Sereact operates as a frontier research lab and a production-grade AI robotics company. The consensus view in our industry is that general-purpose robotic intelligence must begin with models: larger networks, new architectures, or increasingly sophisticated simulations. At Sereact, we hold a contrarian view: general-purpose robotic intelligence must be learned from live deployments.
Data coverage of real-world interaction regimes and distributional alignment between training and deployment are critical. Systems that must perceive, reason, and act under physical constraints operate in a world governed by contact, friction, uncertainty, and long-tail variation. Robots must learn through plentiful interactions and feedback from within the environments in which they are deployed.
Our approach is to build a Real-World Learning Loop. Rather than separating research from deployment, learning is driven directly by production operation. Every successful pick, every failure, and every recovery becomes a rich training signal.
To our knowledge, this approach is novel at industrial scale outside of self-driving cars and is what makes Sereact category-defining.
The Physical AI Data Gap
Empirical evidence across recent robotics research indicates that performance is often constrained more by the availability of large-scale real-world interaction data than by model capacity.
Manipulation is governed by contact-rich dynamics-forces, friction, compliance, and transient contacts-that are only partially observable and poorly represented in most alternative data modalities. Egocentric and exocentric video provide semantic and geometric context, but they do not encode the force and tactile signals that underlie manipulation stability, insertion accuracy, and recovery behavior.
Synthetic data and simulation can approximate these interactions, but only to a limited extent. They rely on simplified contact models and idealized assumptions that fail to capture the domain-specific structure of real environments, such as warehouses, manufacturing sites, and retail stores. These environments exhibit highly non-uniform distributions shaped by industry constraints, human workflows, and hardware wear, which are difficult to reproduce synthetically.
As a result, policies trained predominantly on synthetic or offline data tend to overfit to idealized interaction patterns and degrade under real-world conditions. Robust generalization therefore requires large-scale exposure to real-world interaction data, which anchors learning in the true joint distribution of perception, action, and physical response encountered in deployment.
Generalization, in robotics, emerges from experience, not abstraction alone. That experience must reflect the true distributions of objects, environments, and interactions encountered in production.
The Real-World Learning Loop
The Real-World Learning Loop operationalizes the principle that robust robotic intelligence must be learned through sustained real-world interaction. Instead of decoupling data collection from deployment, learning is driven directly by robots performing production work in customer environments. At any point in time, a large fleet of robots is actively operating across sites, tasks, and conditions, generating continuous streams of interaction data as a byproduct of solving real problems.
Igniting a real-world learning loop is hard. Scaling from a handful of systems to 10, 20, and beyond must occur while meeting strict customer KPIs on uptime, throughput, and reliability. Underperforming systems are quickly removed, and customer trust is difficult to earn; only systems that deliver immediate, reliable value are allowed to scale.
This scale of deployment is essential. With more than 100 physical systems in operation, the Sereact fleet samples a broad range of real-world conditions, including object variability, environmental differences, hardware tolerances, and operational constraints. The data includes not only nominal executions but also failures, near-misses, and recovery behaviors-events that arise naturally in sustained operation.
As models improve, robots internalize real-world physics and system dynamics, closing the learning loop: data compounds, capability improves, and coverage of the interaction space expands. Generalization emerges incrementally from continuous real-world operation, forming the foundation for the learning architecture that follows.
Architecture for continual learning
The learning architecture below shows deployment at the center of the process. All robots feed real-world data into a single, centralized Cortex, which continuously updates policies that are redeployed across the fleet.
In-Situ Policy Execution
The current policy is executed on robots deployed in real-world production environments. Execution is constrained by safety, latency, and reliability requirements, while exposing internal signals relevant for downstream learning. Rather than treating deployment as a fixed endpoint, execution is treated as the primary source of learning signal.
Continuous Data Acquisition
During operation, robots automatically annotate their interactions by recording synchronized sensory observations, robot state, action trajectories, gripper force feedback, and task outcomes-preserving temporal and causal structure and reflecting the relevant distribution encountered in deployment.
Data Curation and Learning
Collected data is filtered and prioritized based on criteria such as novelty, uncertainty, failure events, and distributional shift. Selected samples are used to update model representations and policies, ensuring that learning remains grounded in real-world interaction. This ensures that learning is focused on the long tail of rare and uncertain interactions, driving meaningful generalization.
Evaluation and Policy Redeployment
Updated models are evaluated automatically within a continuous training–evaluation–deployment pipeline using offline metrics and deployment-relevant criteria, including robustness and regression checks. Policies that satisfy predefined validation gates are then rolled out to the fleet in an automated manner, closing the learning loop.
Generalization Grows from Experience (a Byproduct of Deployment)
In robotic manipulation, small variations in geometry, contact conditions, or timing can lead to qualitatively different outcomes, making generalization inherently challenging. Continuous operation in production environments exposes the system to this variation at scale.
As shown in Figure 2, increasing the amount of real-world interaction data leads to a systematic expansion of task competence. With limited real-world data, models succeed on only a narrow subset of tasks, exhibiting uneven and brittle performance. As real-world data becomes the dominant training signal, success rates improve consistently across tasks, producing a denser and more uniform task–performance landscape. These gains emerge only at higher real-world data regimes, indicating that real-world interaction provides transferable structure rather than task-specific tuning.
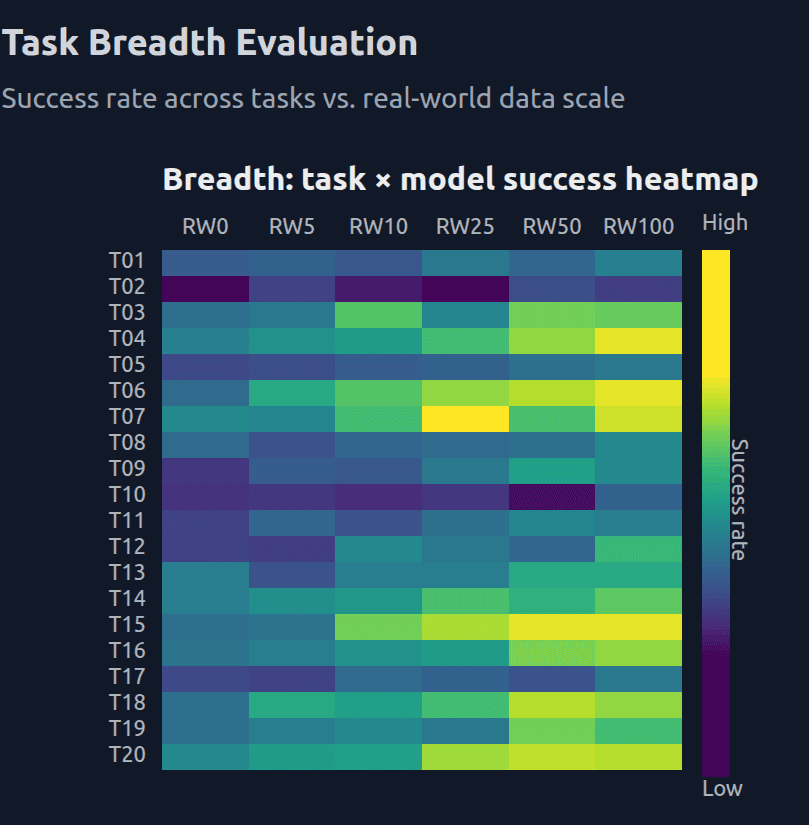
Figure 2. Real-world data scale drives task breadth and generalization. Heatmap of success rates across held-out manipulation tasks as a function of increasing real-world data scale. Higher proportions of real-world interaction data yield broader and more consistent task performance, reflecting improved generalization.
Beyond task generalization, real-world data also enables transfer across robot embodiments. Policies trained on real-world warehouse pick-and-place data generalize substantially better across different robot morphologies than policies trained on simulation-only data. Real-world data yields consistent gains for all platforms. This transfer is enabled because real-world data grounds learning in invariant physical laws and shared manipulation primitives, allowing interaction dynamics to generalize across form factors.
As performance improves, robots can be deployed to more challenging scenarios, further expanding coverage of the interaction space. This creates a compounding effect: additional real-world data not only improves existing task performance, but also lowers the marginal effort required to support new tasks and embodiments. In this regime, generalization emerges naturally as a consequence of operating and learning at scale in the real world, rather than as an explicit optimization objective.
Figure 3. Real-world data enables cross-embodiment generalization.
Normalized generalization efficiency across robot embodiments when training on simulation-only data versus real-world warehouse pick-and-place data. Real-world training yields substantially higher transfer for all embodiments, while simulation-only training shows consistently low cross-embodiment generalization.
A Data & Performance Advantage That Is Impossible to Replicate
Sereact Cortex is built, trained, and deployed in the real world, creating a very strong data and performance advantage. A central consequence of this approach is that data acquisition is inseparable from value creation. Rather than relying on teleoperation or staged data collection-approaches that scale linearly with cost and remain disconnected from customer value-Cortex learns through sustained production execution.
Robots generate data by doing real work. Every successful execution, every recovery, and every failure occurs within a live operational context and carries direct economic relevance. As deployments scale, the system does not merely accumulate more data; it acquires data that is increasingly diverse, distributionally aligned, and representative of real-world constraints. Edge cases are not engineered but encountered naturally through use, and as performance improves, robots are trusted with more complex scenarios, further expanding the learning signal.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles