Fine-Tuning small VLMs

Making Small Vision-Language Models Work in Production
At Sereact we build the AI that runs industrial robots in live production: more than 200 systems across Europe and over a billion real picks. That comes from a deliberate choice to learn from real deployments rather than lab demos: unpredictable orientations, packaging that varies, lighting that shifts, new SKUs every week, and a hard throughput budget on every cell.
We've talked a lot about the planning side, where Cortex 2.0 adds a world model so a robot can weigh several possible actions and rule out bad actions before it moves. But planning is only as good as what the perception model hands it: if the vision-language model at the front of the stack misreads the scene, no amount of downstream reasoning recovers. So this post demonstrates how to get a compact VLM accurate enough to anchor that pipeline, quick to retrain as the floor changes, and fast enough to keep pace with the line. On a benchmark the bigger model usually wins, but on a factory floor that advantage tends to vanish, and reaching all three at once depends on how it's trained.
Motivation
Fine-tuning does several jobs, and they're worth separating because no single training pass covers them all:
- Modality alignment. A text-only language model and a vision encoder are pretrained independently and share no common footing. The visual features mean nothing to the language model until we build the bridge between them.
- Domain adaptation. A general-purpose model covers any one domain thinly. Fine-tuning moves it onto the warehouse data it will actually see.
- Task competence. Naming what's in view is not the same as reasoning about it.
- Reliable precision. Pretraining and instruction-tuning get you to “usually right”; turning that into “verifiably exact” is a separate goal.
- Efficiency of iteration. Real deployments keep changing: a new SKU, different lighting, a reworked layout. A recipe you can re-run in hours is an asset; one you can only afford to run quarterly is a liability.
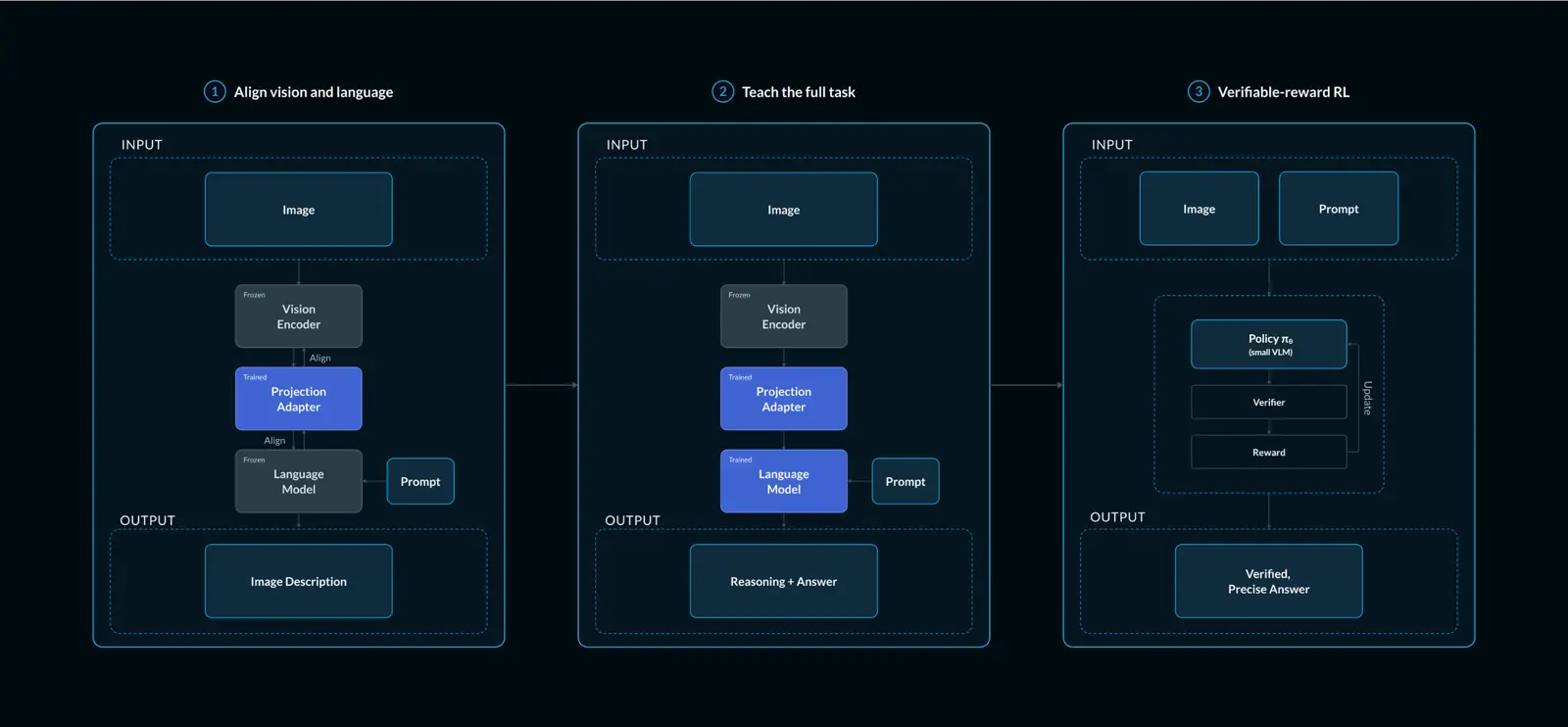
So we split the work into three stages, each handling the objective it's best suited to: connect the vision encoder to the language model so it can see, build task competence with direct supervision, then use verifiable rewards to make the high-stakes answers exact. The order matters: each stage does work the next depends on. On our held-out suite across picking, kitting, and inspection, exact-match accuracy climbs from ~84% after Stage 2 to ~93% after Stage 3.
A note on the data
All three stages are trained on data drawn from the fleet itself: real frames from real cells, which is what keeps the model honest about the orientations, packaging, and lighting it will actually meet. Raw frames alone aren't enough, though, since most of them carry no instruction or target. Following the recipe introduced by LLaVA [1], we extend the fleet imagery with instruction-and-response data generated by a stronger teacher model, prompting it to turn a scene into the kind of question-and-answer or reasoning trace a stage needs. The balance shifts across stages: Stage 1 is largest in raw images but cheapest to label (just captions, a few million pairs), Stage 2 is smaller but richer and most expensive (a few hundred thousand instruction-response pairs with reasoning traces), and Stage 3 is smallest (tens of thousands of prompts), since each needs only a computed verifiable target, not a written answer.
Examples of the task family these stages train on:
Picking
Kitting
Returns Handling
Closing the gap with a smaller model
A small VLM keeps pace with the line and is quick to retrain whenever the task shifts, which in a real deployment is constantly. A bigger model might win on a benchmark, but if it can't answer in the time the line allows it's unusable here, whatever its score. The goal is a model that runs small and fast while still reaching roughly the level of a much larger one on the tasks that matter.
The catch is capability density. A small model has less room to hold both general perception and the specific reasoning a task needs, so trained carelessly it either fails to connect vision to language or memorizes the easy cases and falls apart on the hard ones. Trained in the right order, though, it can close most of that gap, and the three stages below are how, with each one aimed at a different way a small model tends to fail.
Stage 1: Align vision and language
We begin with two parts that were never trained to talk to each other: a pretrained vision encoder that turns an image into visual features, and a text-only language model that has only ever consumed word tokens. The model is wired as a pipeline. The vision encoder produces features from the image, a projector maps those features into the language model's token-embedding space, and the language model then reads them as if they were words and generates text. The text instruction is tokenized and fed directly into the language model, where it joins the visual tokens as one combined sequence. This two-stage recipe follows LLaVA [1].
The projection adapter starts out meaningless: the visual tokens it produces don't correspond to anything in the language model's vocabulary. Stage 1 trains that projector and nothing else. Both the vision encoder and the language model stay frozen, since each already brings strong general-purpose capabilities, and the only parameters that move are the projector's, , under the ordinary supervised next-token objective:

✓Aligned:
“An open kit box, partially filled, with source items staged to the sides.”
✗Misaligned:
“A sealed retail box, ready to ship.”
The data is deliberately simple: a prompt like “describe the image” paired with a caption. The projector's only job is to turn visual features into tokens the frozen language model already understands, in effect a compatible visual tokenizer for it.
The stage is cheap and low-risk, yet skipping it poisons everything after: until the projector is aligned, the language model reasons over visual tokens that mean nothing to it, and anything built on top inherits that confusion.
Picking - Stage 1

Kitting - Stage 1

Returns / Inspection - Stage 1

Stage 2: Teach the harder tasks, end to end
Once the projector lets the model see, you raise the difficulty. The vision encoder stays frozen, but now the projector and the language model train together, so the trainable parameters become . The model stops merely describing scenes and starts answering real questions.
The change from Stage 1 is mostly in the data. The prompts are now the questions the deployment actually asks (“how many bins are in the image,” “is this bin empty,” “which slot still needs filling”), and the target is a short chain of thought followed by the answer. The target splits into a reasoning trace and the final answer , and we supervise the two parts differently, because they are different kinds of target.
The answer is supervised exactly as in Stage 1, with the ordinary next-token loss over the answer span:
The trace needs a lighter touch. Many traces lead to the same answer, so forcing the model to reproduce the teacher's exact wording overfits its phrasing, and when an example carries an empty or trivial trace the plain loss would teach the model that skipping reasoning is the target.
We track the rate of valid reasoning traces alongside accuracy, rather than trusting accuracy alone [2].
This is the stage where the model picks up the competence the task actually needs. It's the most data-hungry of the three, but it's still ordinary supervised learning, which keeps it stable and predictable. By the end you have a model that can see and is broadly capable on the task family, but with two limits that set up the final stage. Supervised fine-tuning (SFT) teaches the model to imitate: it reproduces the teacher's answers well on data that resembles the training set, but generalizes poorly to the long tail the floor actually produces. And each new round of SFT pulls the whole model toward the new task, eroding what it already knew (catastrophic forgetting). Because it only imitates, it isn't reliably precise on the cases where there's a single right answer and being close isn't good enough. Stage 3 sidesteps all of this: optimizing a verifiable reward instead of imitating fixed tokens makes the high-stakes answers precise and pushes the model past mimicry toward reasoning that transfers, without overwriting everything else.
Picking - Stage 2

Kitting - Stage 2

Returns / Inspection - Stage 2

Stage 3: Reinforcement learning with verifiable rewards
The final stage targets that precision. Instead of learning a separate reward model, we compute the reward directly from whether the answer is right. Dropping the learned reward model is what keeps the stage affordable on a small-model budget.
The optimizer is GRPO (Group Relative Policy Optimization) [3]. The policy (the small VLM itself) samples a group of candidates per prompt, scores each against the verifiable target, and standardizes the rewards within the group so the group itself supplies the baseline:
That advantage drives a clipped policy-gradient update, the same surrogate as PPO but with the group baseline in place of a learned critic. With the per-token importance ratio
Since every candidate shares the same advantage , the whole reasoning trace behind a good answer is reinforced, not just the final token. We use DAPO [3] rather than vanilla GRPO: it decouples the clip range () to keep exploration alive, drops the normalizations that bias toward longer outputs, and aggregates the loss at the token level. This trains more stably and keeps outputs short, which is what keeps the deployed model fast.
The reward depends on the task's answer type, and the two cases are worth stating explicitly. When there is a single definite answer, a category, a yes/no, a discrete label, the reward is an indicator that fires only on an exact match:
When the answer is a numeric or measurable quantity, all-or-nothing wastes signal. The reward instead scales with how close the prediction lands to the target, giving partial credit for being near and a stronger signal for being exact, for a tolerance :
Either way, supervision comes from the task itself, not from a human rater or a learned proxy: the function scoring the model is the same one you'd use to check it in production.
Picking - Stage 3

Kitting - Stage 3

Returns / Inspection - Stage 3

Why the order matters
The three stages aren't interchangeable. Alignment first, because reasoning on top of misaligned features is reasoning about the wrong thing. Broad supervised competence second, because RL sharpens a capability that already exists but can't manufacture one from nothing. Verifiable-reward RL last, because its job is to convert “usually right” into “reliably exact” on the cases that have a checkable answer.
Run in that order, each stage does work the next one depends on, and none is asked to do a job it's bad at. The result is a small model that aligns properly, reasons on the real task, and hits the precision an industrial use case actually requires, trained and served at a cost that fits the deployment rather than fighting it.
Takeaway
Making small VLMs work in production isn't about clever shrinking. It's about staging the training so a compact model spends its limited capacity well: align vision and language, build task competence with direct supervision, then use verifiable rewards to make the high-stakes answers precise. Dropping the learned reward model in that last stage isn't a compromise, it's the move that keeps the whole pipeline efficient enough to retrain as often as a real deployment demands.
References
[1] Liu, Li, Wu, Lee. Visual Instruction Tuning (LLaVA). NeurIPS 2023. arXiv:2304.08485.
[2] Twist, Yannakoudakis, Zhang. Reasoning-Trace Collaps: Evaluating the Loss of Explicit Reasoning During Fine-Tuning 2026. arXiv:2605.21127.
[3] Shao et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. 2024. arXiv:2402.03300.
[4] Yu et al. DAPO:An Open-Source LLM Reinforcement Learning System at Scale. NeurIPS 2025. arXiv:2503.14476.
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles