Cortex: Bridging Vision, Language, and Action with Discrete Plans and Tokens

Robots are moving from the lab to the real world, and Cortex is designed to make them truly adaptable. As they are steadily entering our homes, workplaces, and warehouses, they are expected to handle a wide range of tasks in a variety of environments, from acrobatic maneuvers to everyday household chores. But so far, robots have mainly performed these tasks in controlled settings or during carefully planned demonstrations. Yet, what’s still missing is adaptability and autonomy, be it when moving into an unknown setting, when understanding what needs to be done, and when reliably carrying out tasks without extensive retraining. This gap between demonstrations and true generalization is the main barrier to deploying robots at scale in everyday life.
The introduction of the GPT models has shifted AI research towards large language models (LLMs), which are now inspiring a new trend in robotics. While most robotic “foundation models” are built on top of language models, LLMs were designed for understanding text and semantics and are not made to reason and act in dynamic, three-dimensional worlds. As a result, robots often struggle when asked to generalize, for example when picking up an object they’ve never seen before or figuring out where it belongs in a cluttered environment. To operate reliably, they need to combine common sense with low-level control, all while staying flexible to novel situations.
Vision–Language–Action (VLA) models have emerged as a promising way to address these challenging tasks. By linking visual inputs, natural language, and motor actions, they allow robots to follow instructions in a grounded, context-aware manner. Early versions, however, have exposed a tradeoff: too much optimization for actions can erode a model’s language skills, while focusing solely on language can impede the system's ability for physical tasks. Similar to exploration and exploitation, the challenge is to find a balance between reliability and generalization in real-world robotics.
Our team at Sereact has been tackling this problem in one of the toughest real-world environments: live warehouse operations. Unlike controlled lab settings, fulfillment centers are adversarial, with reflective and deformable objects that constantly change as tasks evolve. To succeed in such conditions, we’ve found three ingredients to be essential: (1) training on real operational data, not just simulated environments and controlled scenarios, (2) enriching perception with depth and mask signals for stronger grounding, and (3) introducing high-level planning layers that guide low-level controllers with explicit subgoals.
This leads us to a central question:
How can we preserve a model’s rich language and reasoning skills while also teaching it to act effectively in the real world?
Our answer is to introduce intermediate structure: discrete plans and tokenized representations of actions and outcomes. These tokens act as a bridge between abstract semantics and precise robot control, enabling models that are both expressive and reliable.
Cortex is our next step in this direction: a Vision-Language-Action (VLA) system that unites vision, language, and action through discrete planning layers. By combining interpretability, robustness, and generalization, Cortex brings us closer to robots that can succeed not only in structured factory environments but also in unstructured and adversarial real-world settings.
How does Cortex work?
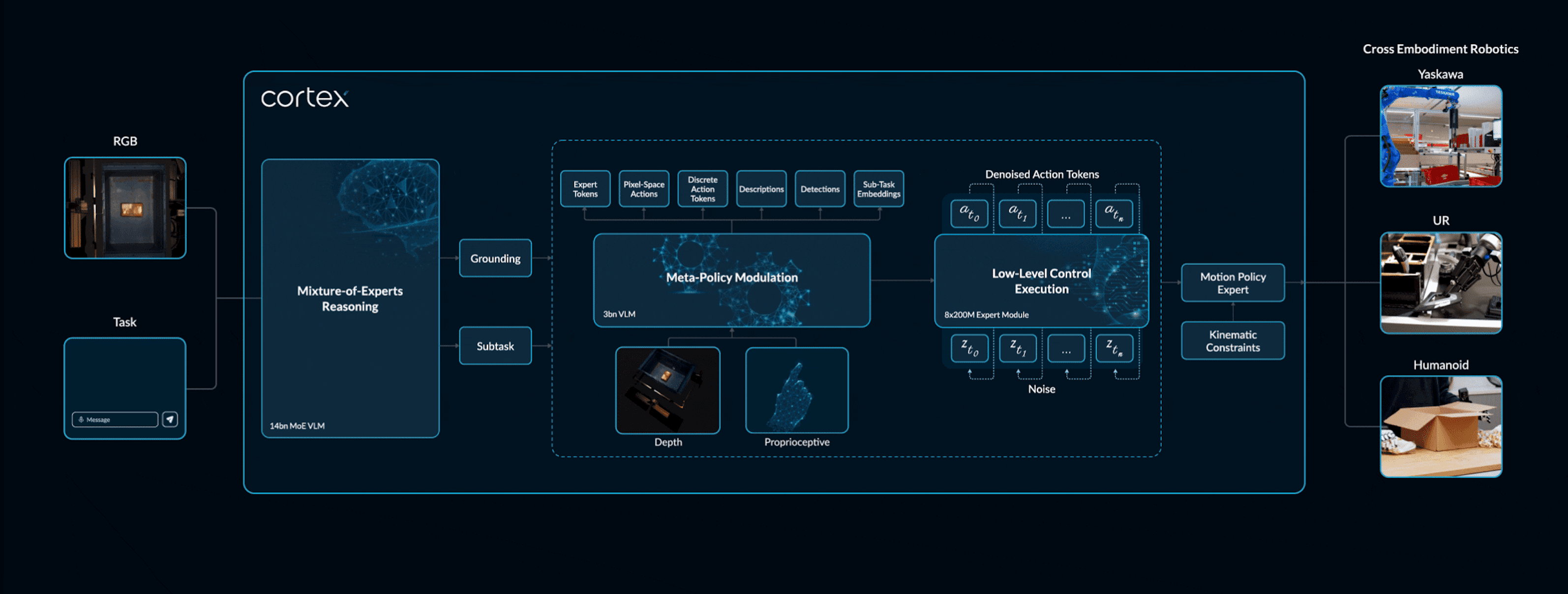
Cortex VLA is our vision–language–action model designed to bring perception, reasoning, and control into a single system. It processes natural language instructions alongside visual input, interprets them, and produces corresponding robot actions. At the core of this loop is our Sereact Lens VLM, which predicts symbolic subtasks and identifies the key regions of a scene where actions should occur.
Instead of translating text instructions directly into raw motor commands, Cortex reasons in layers. It begins by understanding the instruction, grounds it in the visual scene, generates a coarse 3D plan, and then refines this plan into detailed motion predictions. A Motion Policy Expert finally adapts these predictions to the control space of a specific robot. This layered approach preserves language understanding while producing grounded, spatially accurate actions. It also makes Cortex adaptable: the same high-level plan can be executed on different robot types by only fine-tuning the motor actions.
Cortex is still in its early stages, but results are promising. Trained on a growing mix of industrial data and real-world deployment logs, it already demonstrates the ability to generalize to new tasks and environments. As training and refinement continue, Cortex is set to become a robust and versatile foundation for general-purpose robotics.
Discrete Actions: Speaking the Language of Motion
Cortex lets robots ‘speak’ motion the way language models can output words: through discrete tokens. Instead of directly predicting joint angles or velocities, movements are expressed as tokens in a vocabulary. This allows action generation to operate like sentence generation, enabling a straightforward transfer of the reasoning capabilities of language models to robot control.
Across the field, researchers have shown that treating actions as sequences of tokens makes models more efficient, easier to train, and more interpretable. By breaking actions into motion “chunks” or planning streams, such as perception, planning, and execution, models can reason step by step and even expose their thought process, allowing humans to inspect, explain, or steer the predicted robot trajectories.
At Sereact, we extend this idea further by tokenizing not only actions but also perception. Using a custom auto-encoder, we compress video data gathered from both datasets and our deployed robots into video tokens, capturing the complexity of real-world operations. Leveraging data from hundreds of our robots working in warehouses and manufacturing plants, these tokens capture the diversity, clutter, noise, and nuances of real-world operations. The result is a discrete, language-like vocabulary for both what robots see and what they do.
Continuous Action Expert: Low Latency, High Fidelity
Discrete tokens are great for teaching a model how to “think” about actions at scale, but real robots also need smooth, fast control. To bridge that gap, we add a compact continuous action expert that turns the model’s current context into a short chunk of real-valued actions in one go. Instead of spelling out the next movements token by token, the expert produces a small window of precise joint updates or end effector motions that the controller can execute immediately.
In practice this keeps latency low. We cache the vision and language context once, then the expert generates the next action chunk with only a few refinement steps. The result feels responsive on hardware while still following the high level plan formed by the token path.
Training happens in two stages. First we pretrain the backbone with discrete action tokens, which scales well and stabilizes learning across mixed data sources. Then we fine tune the expert on continuous actions with a trajectory matching loss, while keeping the token objective in place for the backbone. We prevent the expert from “peeking” at ground truth tokens so each pathway learns its own job.
Keeping both pathways pays off. Tokens give us strong reasoning, easy inspection, and clean data mixing. The expert delivers smooth motion and quick reactions in the control loop. A simple safety layer sits after the expert to enforce limits, filter spikes, and fall back to the token pathway or a recovery skill when uncertainty is high.
Training Recipes for Generalization and Efficiency
Another clear lesson from the current research is that smarter training strategies often outperform brute-force scaling. Pre-training on broad multimodal data helps models keep their language and reasoning skills, while careful fine-tuning on robot actions layers in physical execution. Researchers are also finding that structured curricula and discrete supervision makes models more generalizable than simply adding more data.
At Sereact, we follow a similar approach. Our in-house VLM, Sereact Lens, is first trained on vision, language, and reasoning. We then use it to automatically label subtasks in robot demonstration videos, effectively eliminating costly manual annotation while producing consistent and scalable supervision. Combined with our massive real-world dataset, this aligns Cortex with both broad reasoning ability and precise control.
Because Cortex models everything (images, text, video, and actions) as a unified token sequence, we can reuse the same efficient training infrastructure built for large language models. Fine-tuning for robotics is lightweight yet powerful enough to quickly adapt Cortex to real-world conditions.
The bottom line: generalist robots come from smart training, not just scale. At Sereact, we iterate fast, improve steadily, and ensure our robots inherit both the reasoning of generalized multimodal AI and the precision and experience of industrial processes.
The Road Ahead: Toward Generalist Visual-Language Agents
We believe that the next generation of vision-language-action (VLA) models will be defined by advances in subtask reasoning, visual foresight, discrete tokenization, and large-scale real-world training. Together, these components will enable agents that combine the fluency of LLMs with grounded physical intelligence.
At Sereact, we are continuously developing and working towards our vision: “One Model, Any Robot”. Cortex builds on our earlier work with Sereact Lens and PickGPT, representing our next step in this vision. In the coming months, we are:
- Systematically benchmarking Cortex, measuring performance on both simulated and real-world tasks, and providing direct comparisons to existing approaches.
- Iteratively improving the training recipe, refining planning layers, tokenization strategies, and control policies to reduce the gap between research and deployment.
- Scale training on larger and more diverse datasets gathered from our fleet of industrial robots, further enhancing generalization to new tasks and embodiments.
- Broaden deployments, testing Cortex on a wider variety of robots and environments to assess adaptability beyond controlled settings.
Our long-term goal is to build a system that can decompose instructions, orchestrate precise actions, and anticipate outcomes, while remaining interpretable and adaptable. By moving from qualitative demonstrations towards rigorous benchmarks and production-ready deployments, we aim to accelerate progress towards an era of flexible, intelligent autonomy, effectively closing the gap between what robots are told to do and what they can truly understand.
Stay tuned for upcoming updates on Cortex!
Article Resources
Access content and assets from this post
Text Content
Copy the full article text to clipboard for easy reading or sharing.
Visual Assets
Download all high-resolution images used in this article as a ZIP file.
Latest Articles